|
Full Publications
 |
Liang-Chieh (Jay) Chen
Research Scientist, Apple AI/ML
Email: lcchen at cs dot ucla dot edu
[google-scholar]
|
Full Publication List
 |
Taming Outlier Tokens in Diffusion Transformers
Xiaoyu Wu, Yifei Wang, Tsu-Jui Fu, Liang-Chieh Chen, Zhe Gan, Chen Wei
Technical Report.
[preprint (arxiv: 2605.05206)]
|
 |
Large Language Models are Universal Reasoners for Visual Generation
Sucheng Ren, Chen Chen, Zhenbang Wang, Liangchen Song, Xiangxin Zhu, Alan Yuille, Liang-Chieh Chen, Jiasen Lu
Technical Report.
[preprint (arxiv: 2605.04040)]
|
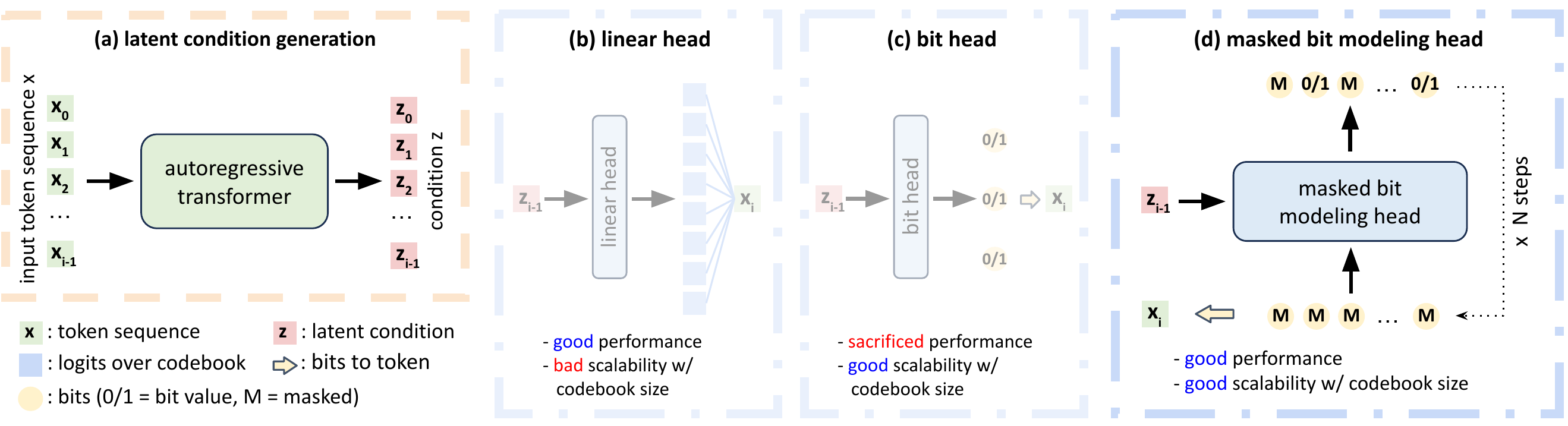 |
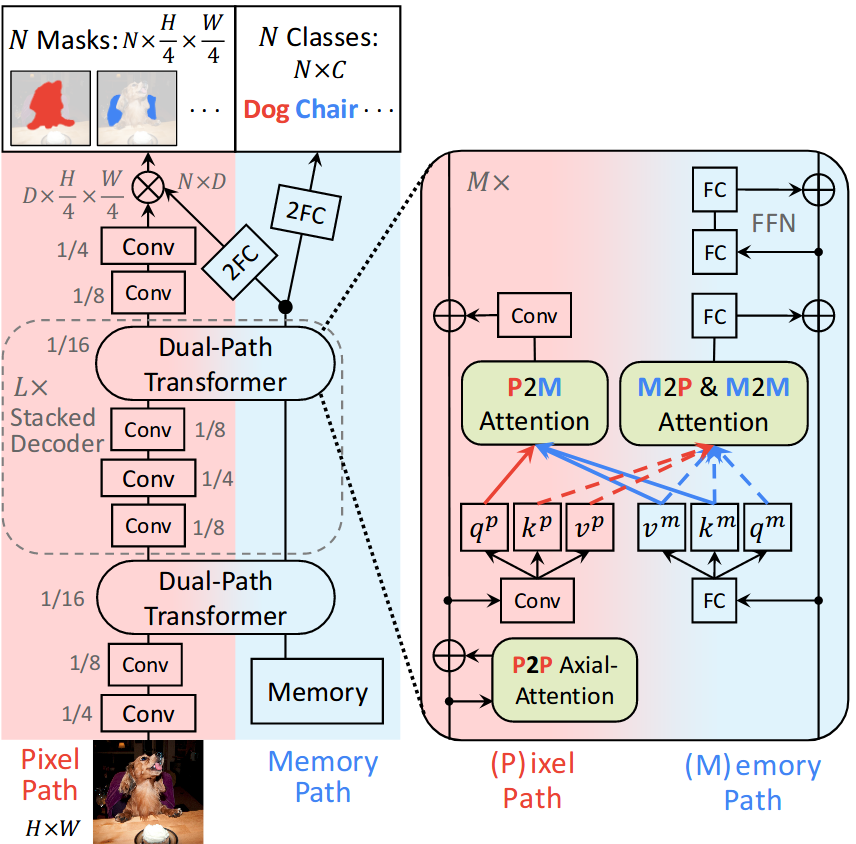
Autoregressive Image Generation with Masked Bit Modeling
Qihang Yu, Qihao Liu, Ju He, Xinyang Zhang, Yang Liu, Liang-Chieh Chen*, Xi Chen*
(*equal advising)
In International Conference on Machine Learning (ICML), Seoul, South Korea, July 2026.
[preprint (arxiv: 2602.09024)] [project website] [code]
|
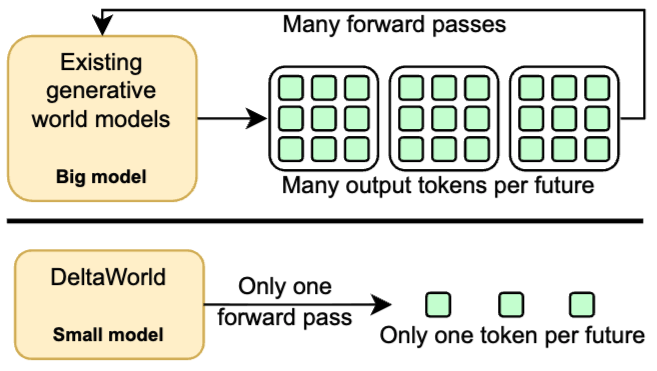 |
A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens (highlight)
Tommie Kerssies, Gabriele Berton, Ju He, Qihang Yu, Wufei Ma, Daan de Geus*, Gijs Dubbelman*, Liang-Chieh Chen*
(*equal advising)
In Conference on Computer Vision and Pattern Recognition (CVPR), Denver, Colorado, USA, June 2026.
[preprint (arxiv: 2604.04913)] [project website] [code]
|
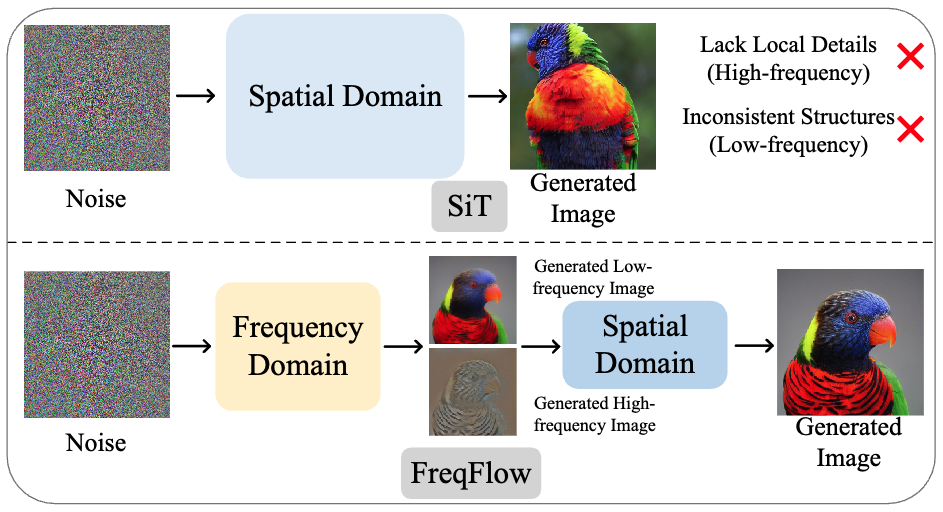 |
Frequency-Aware Flow Matching for High-Quality Image Generation
Sucheng Ren, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen
In Conference on Computer Vision and Pattern Recognition (CVPR), Denver, Colorado, USA, June 2026.
[preprint (arxiv: 2604.15521)] [code]
|
 |
ReVision: High-Quality, Low-Cost Video Generation with Explicit 3D Physics Modeling for Complex Motion and Interaction
Qihao Liu, Ju He, Qihang Yu, Liang-Chieh Chen*, Alan Yuille*
(*equal advising)
Transactions on Machine Learning Research (TMLR), January 2026.
[preprint (arxiv: 2504.21855)] [project website]
|
 |
COCONut-PanCap: Joint Panoptic Segmentation and Grounded Captions for Fine-Grained Understanding and Generation
Xueqing Deng, Qihang Yu, Ali Athar, Chenglin Yang, Linjie Yang, Xiaojie Jin, Xiaohui Shen, Liang-Chieh Chen
In Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks, San Diego, California, USA, December 2025.
[preprint (arxiv: 2502.02589)] [project website]
|
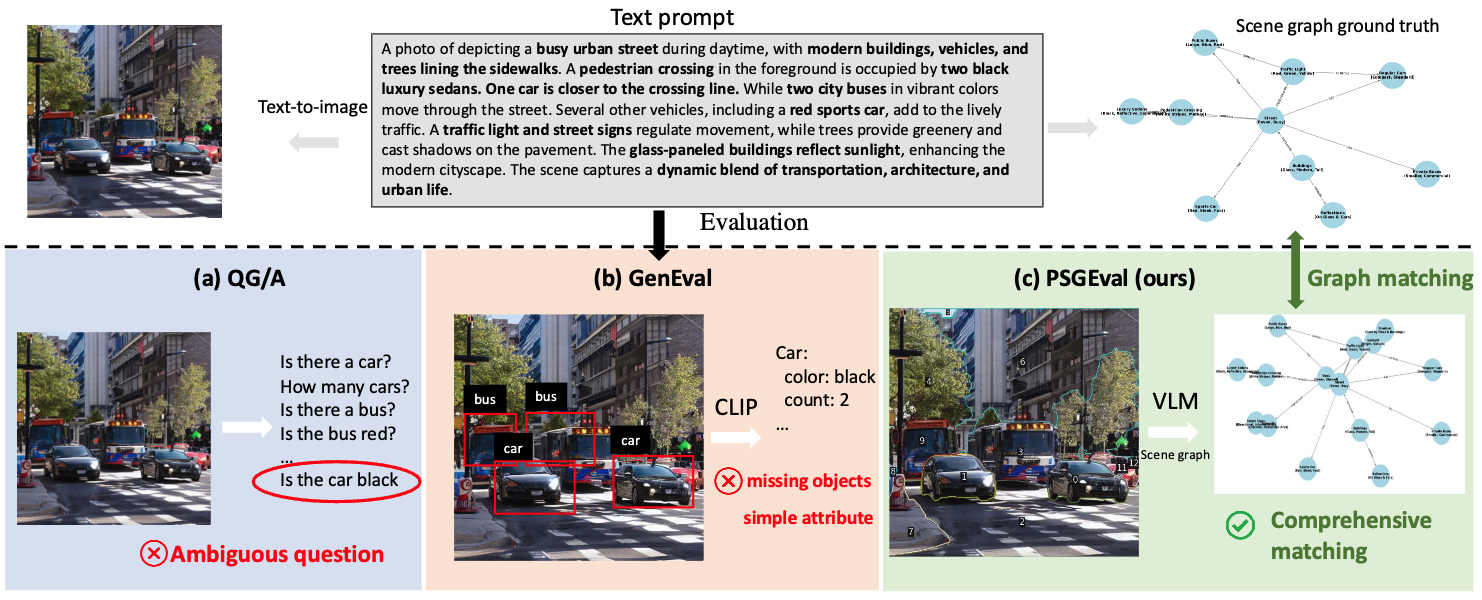 |
Leveraging Panoptic Scene Graph for Evaluating Fine-Grained Text-to-Image Generation
Xueqing Deng, Linjie Yang, Qihang Yu, Chenglin Yang, Liang-Chieh Chen
In International Conference on Computer Vision (ICCV), Honolulu, Hawaii, USA, October 2025.
[paper] [project website]
|
 |
Deeply Supervised Flow-Based Generative Models
Inkyu Shin, Chenglin Yang, Liang-Chieh Chen
In International Conference on Computer Vision (ICCV), Honolulu, Hawaii, USA, October 2025.
[preprint (arxiv: 2503.14494)] [project website] [code]
|
 |
FlowTok: Flowing Seamlessly Across Text and Image Tokens
Ju He, Qihang Yu, Qihao Liu, Liang-Chieh Chen
In International Conference on Computer Vision (ICCV), Honolulu, Hawaii, USA, October 2025.
[preprint (arxiv: 2503.10772)] [project website] [code]
|
 |
Beyond Next-Token: Next-X Prediction for Autoregressive Visual Generation
Sucheng Ren, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen
In International Conference on Computer Vision (ICCV), Honolulu, Hawaii, USA, October 2025.
[preprint (arxiv: 2502.20388)] [project website] [code]
|
 |
Democratizing Text-to-Image Masked Generative Models with Compact Text-Aware One-Dimensional Tokens
Dongwon Kim*, Ju He*, Qihang Yu*, Chenglin Yang, Xiaohui Shen, Suha Kwak, Liang-Chieh Chen
(*equal contribution)
In International Conference on Computer Vision (ICCV), Honolulu, Hawaii, USA, October 2025.
[preprint (arxiv: 2501.07730)] [project website] [code]
|
 |
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
Sucheng Ren, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen
In International Conference on Machine Learning (ICML), Vancouver, Canada, July 2025.
[preprint (arxiv: 2412.15205)] [code]
|
 |
Randomized Autoregressive Visual Generation
Qihang Yu, Ju He, Xueqing Deng, Xiaohui Shen, Liang-Chieh Chen
In International Conference on Computer Vision (ICCV), Honolulu, Hawaii, USA, October 2025.
[preprint (arxiv: 2411.00776)] [project website] [code]
|
 |
MaskBit: Embedding-free Image Generation via Bit Tokens
Mark Weber, Lijun Yu, Qihang Yu, Xueqing Deng, Xiaohui Shen, Daniel Cremers, Liang-Chieh Chen
Transactions on Machine Learning Research (TMLR), December 2024. (Featured and Reproducibility Certifications)
[preprint (arxiv: 2409.16211)] [project website] [code]
|
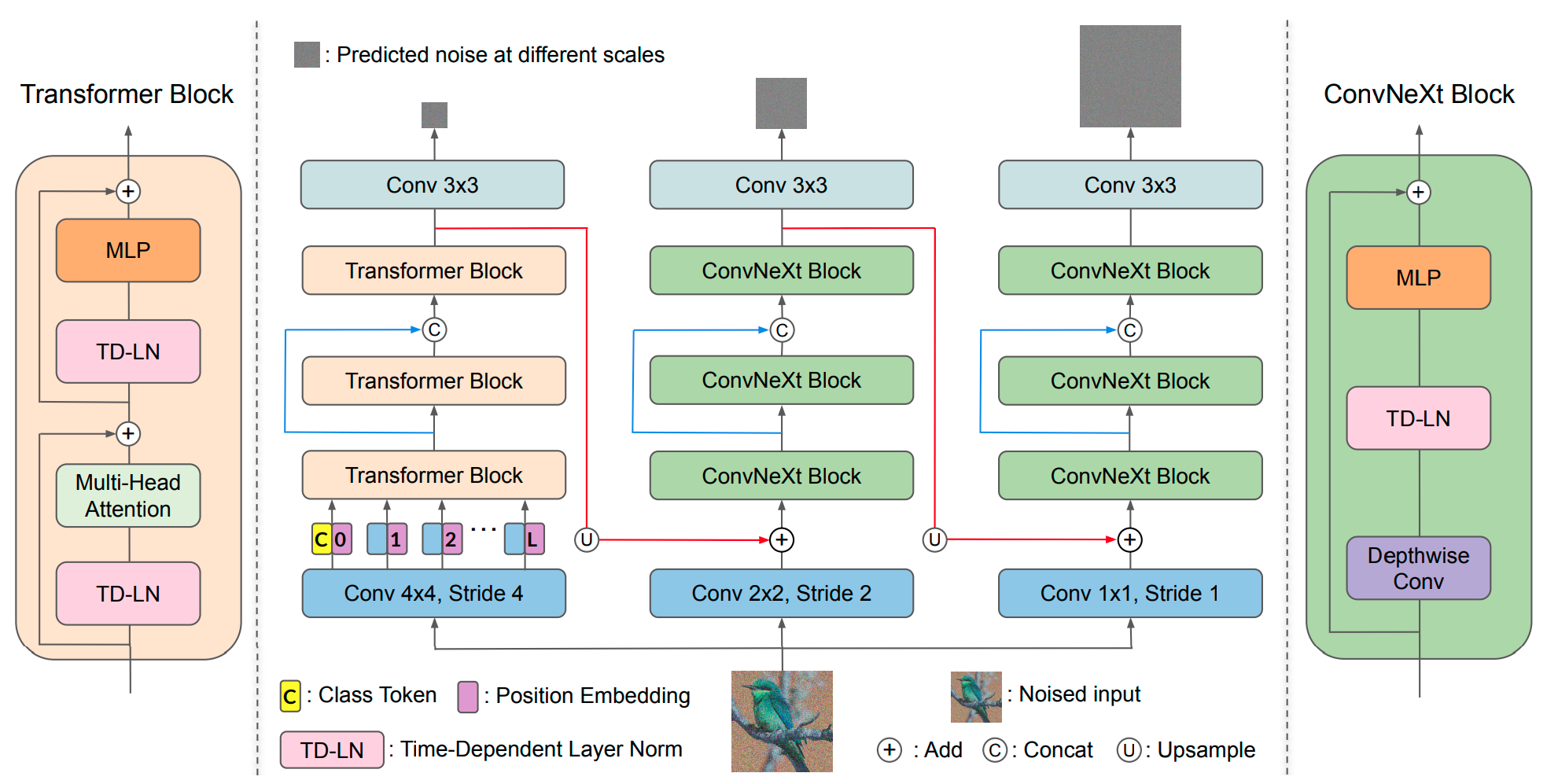 |
Alleviating Distortion in Image Generation via Multi-Resolution Diffusion Models
Qihao Liu*, Zhanpeng Zeng*, Ju He*, Qihang Yu, Xiaohui Shen, Liang-Chieh Chen
(*equal contribution)
In Neural Information Processing Systems (NeurIPS), Vancouver, Canada, December 2024.
[preprint (arxiv: 2406.09416)] [project website] [code]
|
 |
An Image is Worth 32 Tokens for Reconstruction and Generation
Qihang Yu*, Mark Weber*, Xueqing Deng, Xiaohui Shen, Daniel Cremers, Liang-Chieh Chen
(*equal contribution)
In Neural Information Processing Systems (NeurIPS), Vancouver, Canada, December 2024.
[preprint (arxiv: 2406.07550)] [project website] [code]
|
 |
Enhancing Temporal Consistency in Video Editing by Reconstructing Videos with 3D Gaussian Splatting
Inkyu Shin, Qihang Yu, Xiaohui Shen, In So Kweon, Kuk-Jin Yoon, Liang-Chieh Chen
Transactions on Machine Learning Research (TMLR), March 2025.
[preprint (arxiv: 2406.02541)] [project website] [code]
|
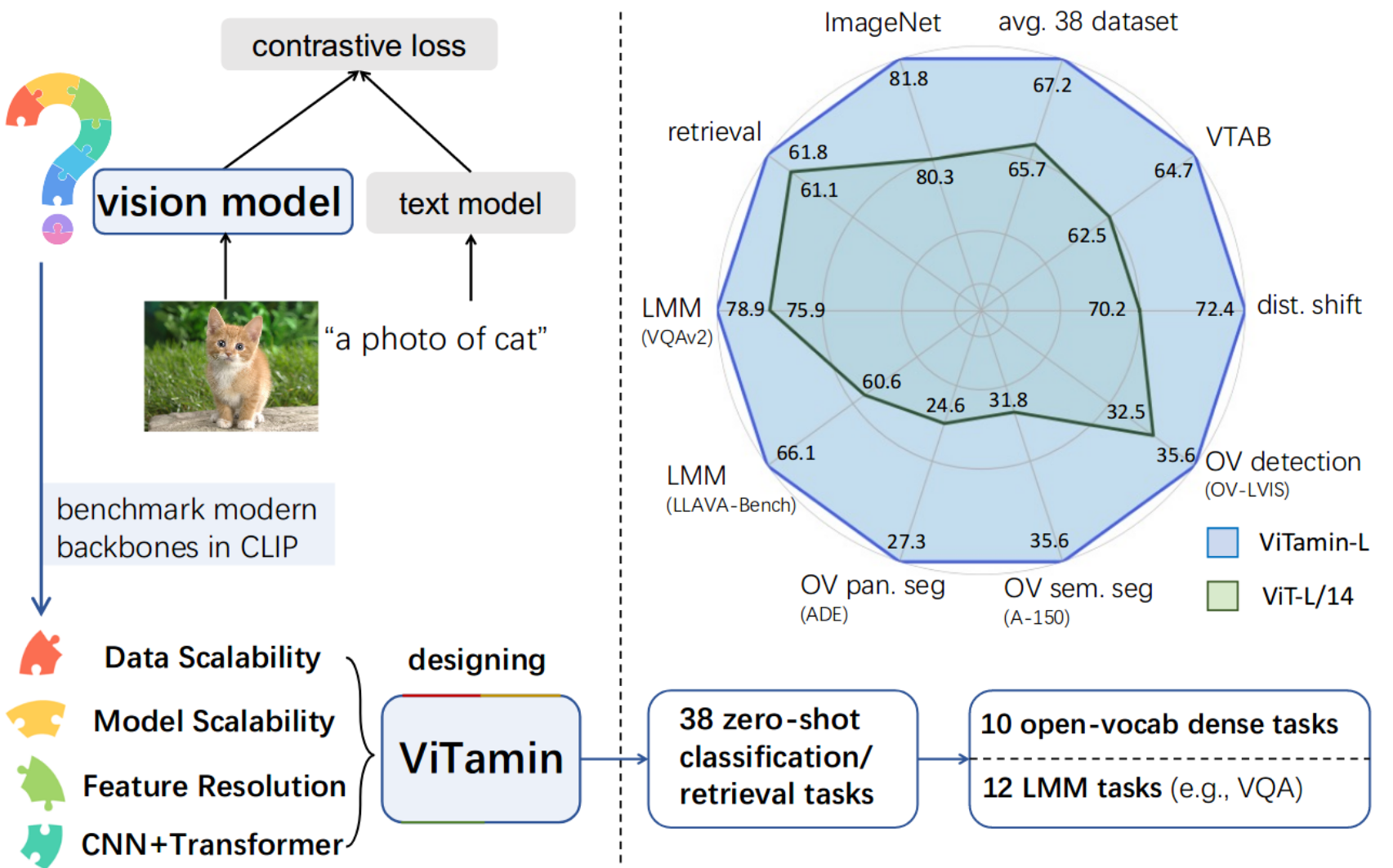 |
ViTamin: Designing Scalable Vision Models in the Vision-Language Era
Jieneng Chen*, Qihang Yu*, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen
(*equal contribution)
In Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, Washington, USA, June 2024.
[preprint (arxiv: 2404.02132)] [project website] [code] [HuggingFace]
|
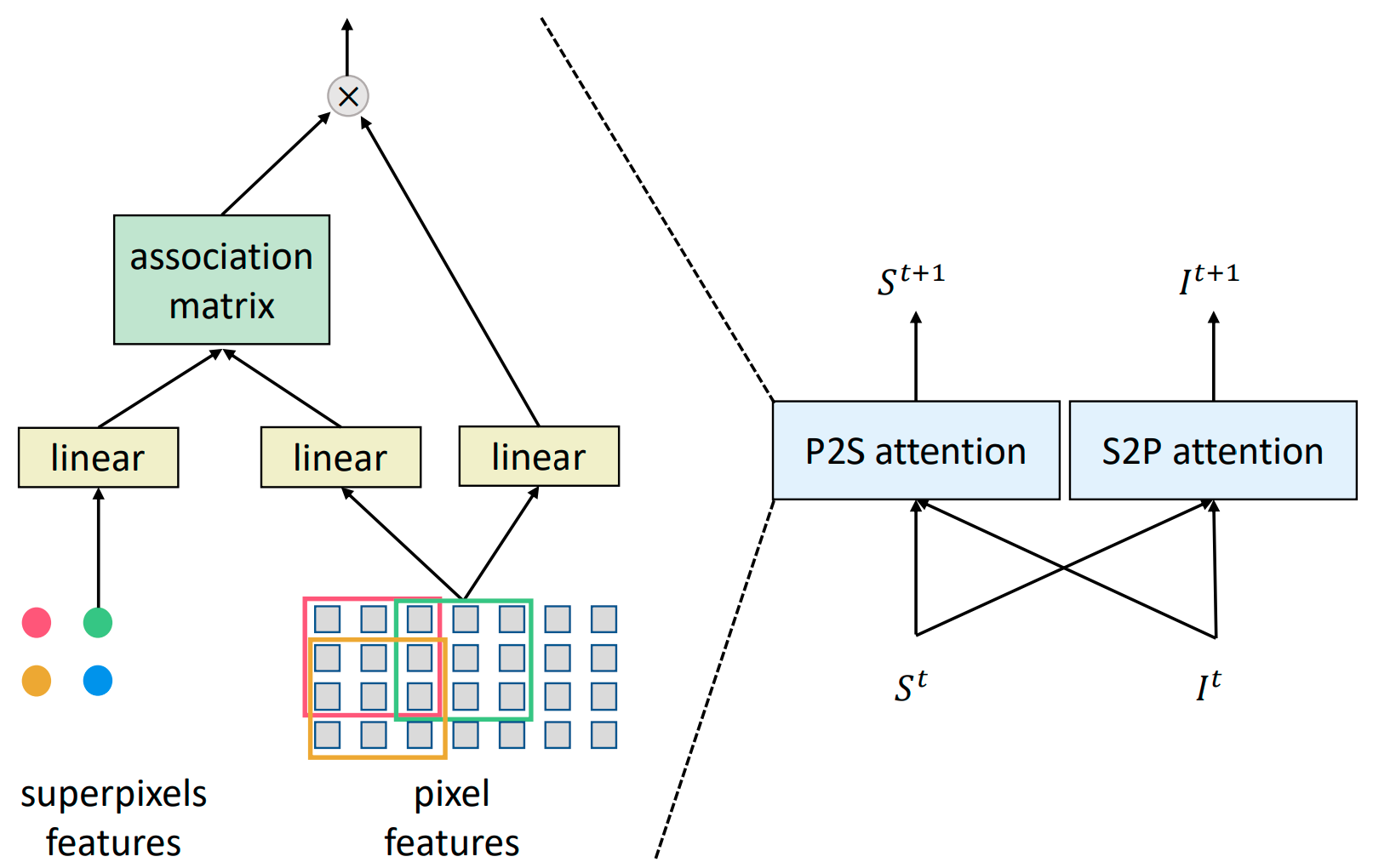 |
SPFormer: Enhancing Vision Transformer with Superpixel Representation
Jieru Mei, Liang-Chieh Chen, Alan Yuille, Cihang Xie
Transactions on Machine Learning Research (TMLR), December 2024.
[preprint (arxiv: 2401.02931)]
|
 |
MaXTron: Mask Transformer with Trajectory Attention for Video Panoptic Segmentation
Ju He, Qihang Yu, Inkyu Shin, Xueqing Deng, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen
Transactions on Machine Learning Research (TMLR), June 2024.
[preprint (arxiv: 2311.18537)] [PyTorch code]
|
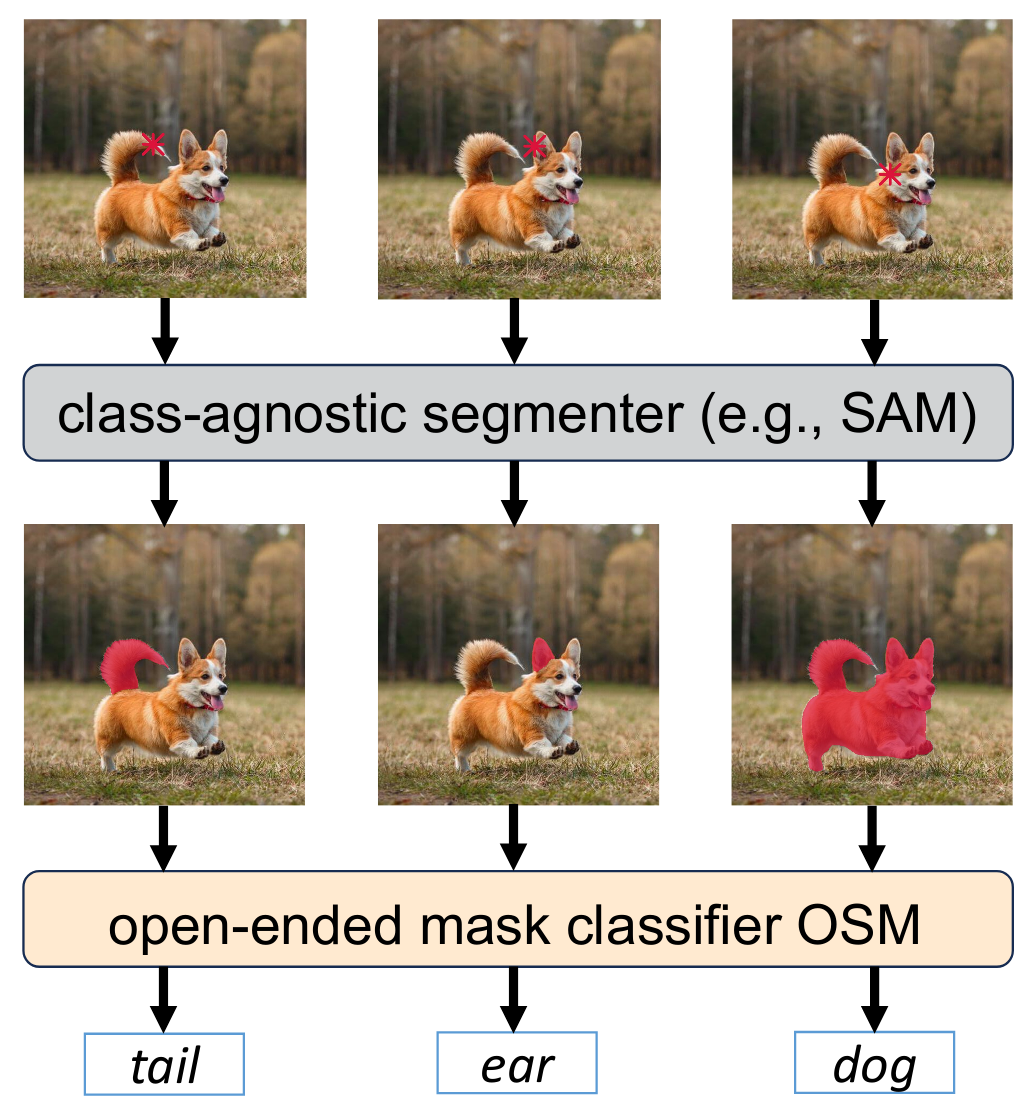 |
Towards Open-Ended Visual Recognition with Large Language Model
Qihang Yu, Xiaohui Shen, Liang-Chieh Chen
In European Conference on Computer Vision (ECCV), Milan, Italy, September 2024.
[preprint (arxiv: 2311.08400)] [PyTorch code]
|
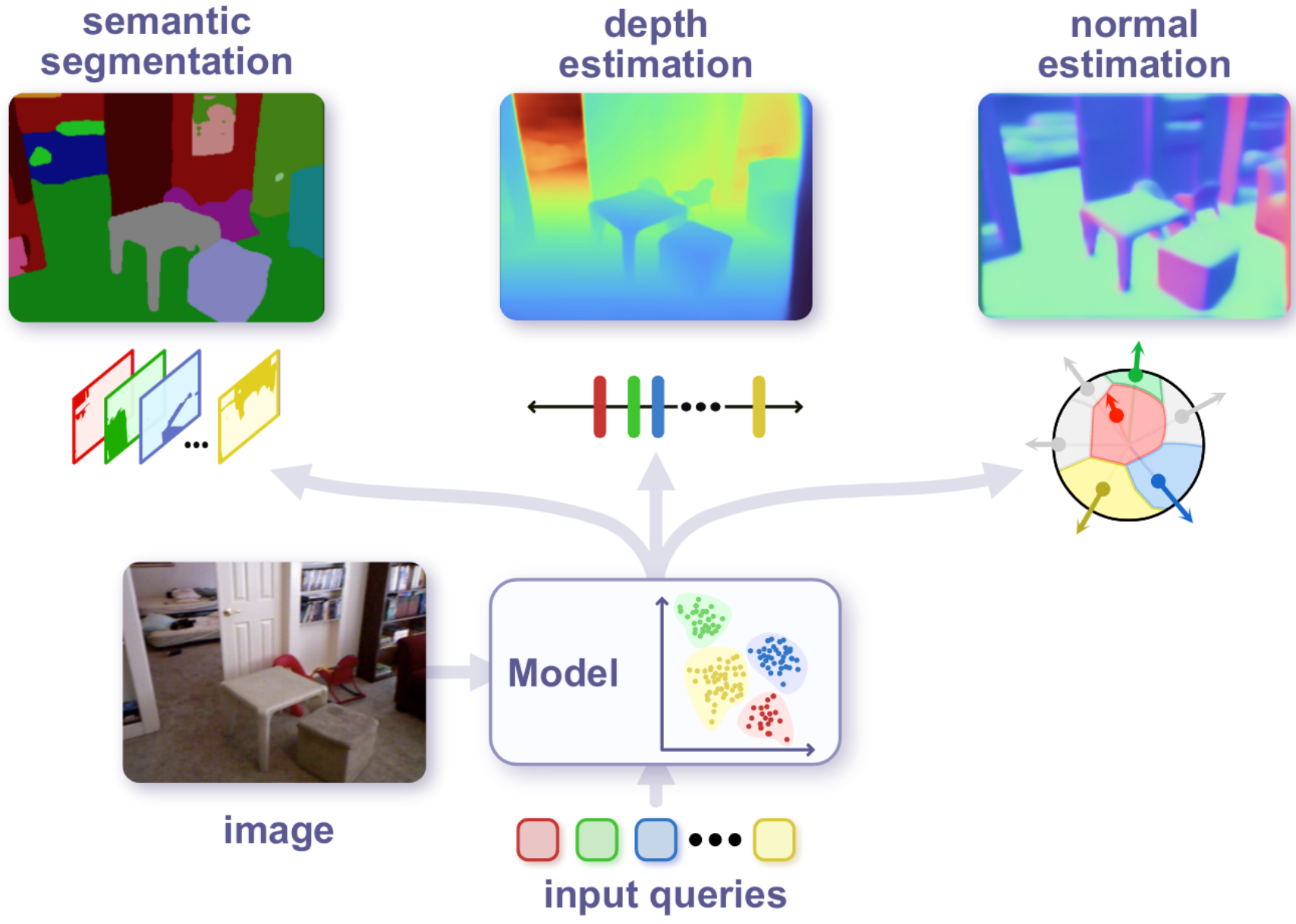 |
PolyMaX: General Dense Prediction with Mask Transformer
Xuan Yang, Liangzhe Yuan, Kimberly Wilber, Astuti Sharma, Xiuye Gu, Siyuan Qiao, Stephanie Debats, Huisheng Wang, Hartwig Adam, Mikhail Sirotenko, Liang-Chieh Chen
In Winter Conference on Applications of Computer Vision (WACV), Waikoloa, Hawaii, USA, January 2024.
[preprint (arxiv: 2311.05770)]
|
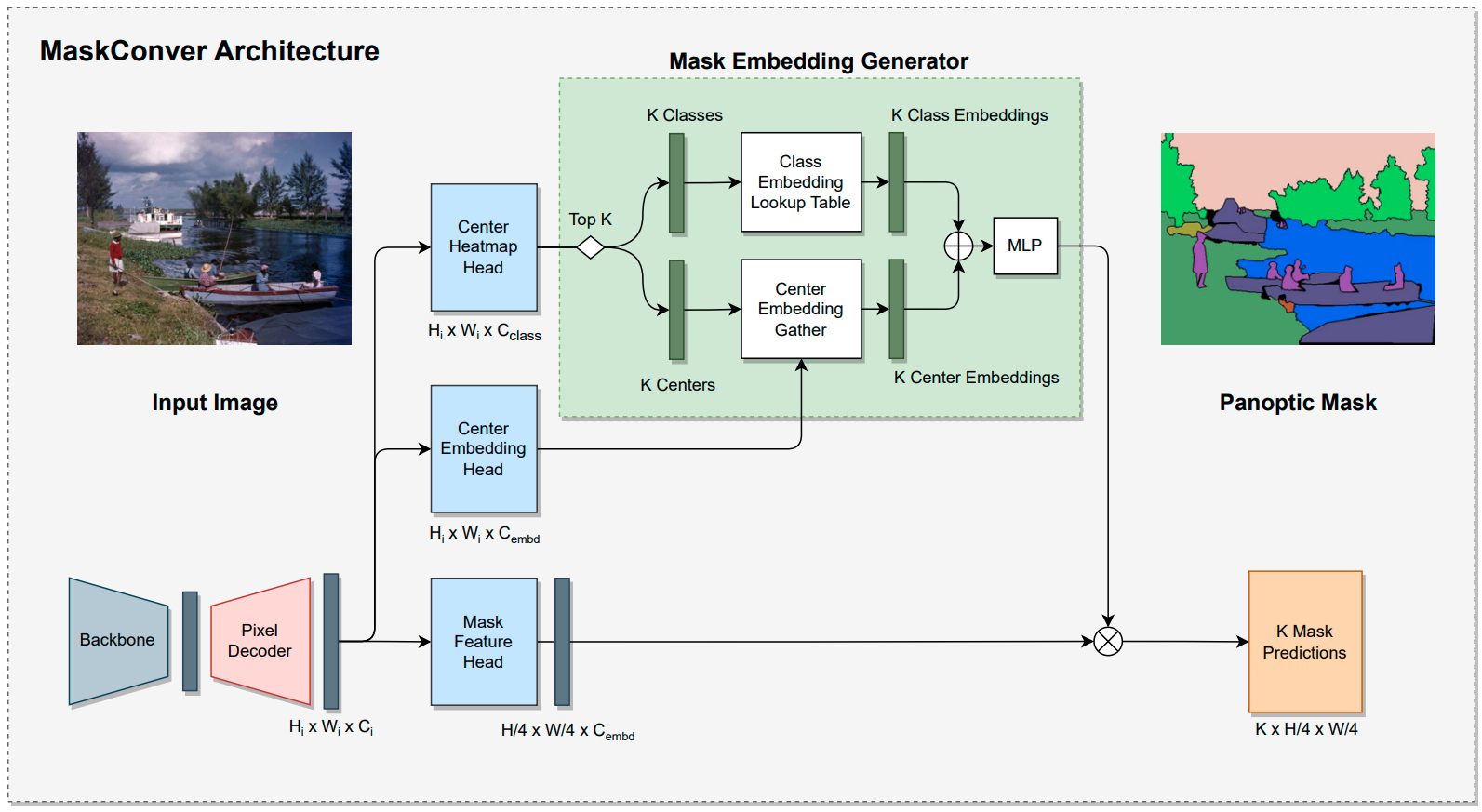 |
MaskConver: Revisiting Pure Convolution Model for Panoptic Segmentation
Abdullah Rashwan, Jiageng Zhang, Ali Taalimi, Fan Yang, Xingyi Zhou, Chaochao Yan, Liang-Chieh Chen, Yeqing Li
In Winter Conference on Applications of Computer Vision (WACV), Waikoloa, Hawaii, USA, January 2024.
[preprint (arxiv: 2312.06052)]
|
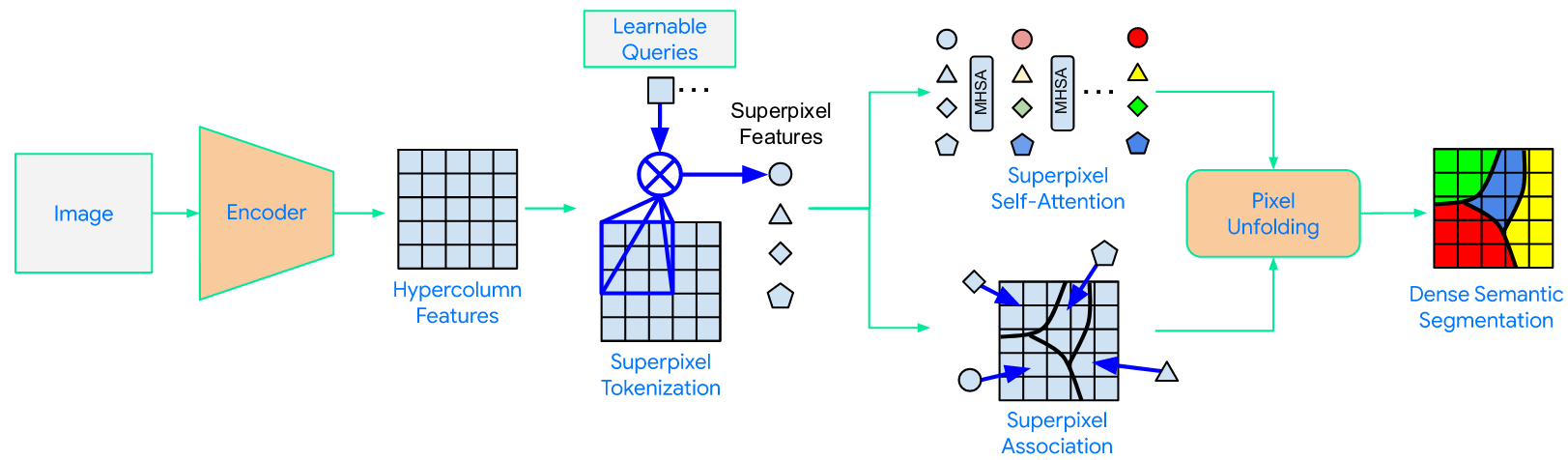 |
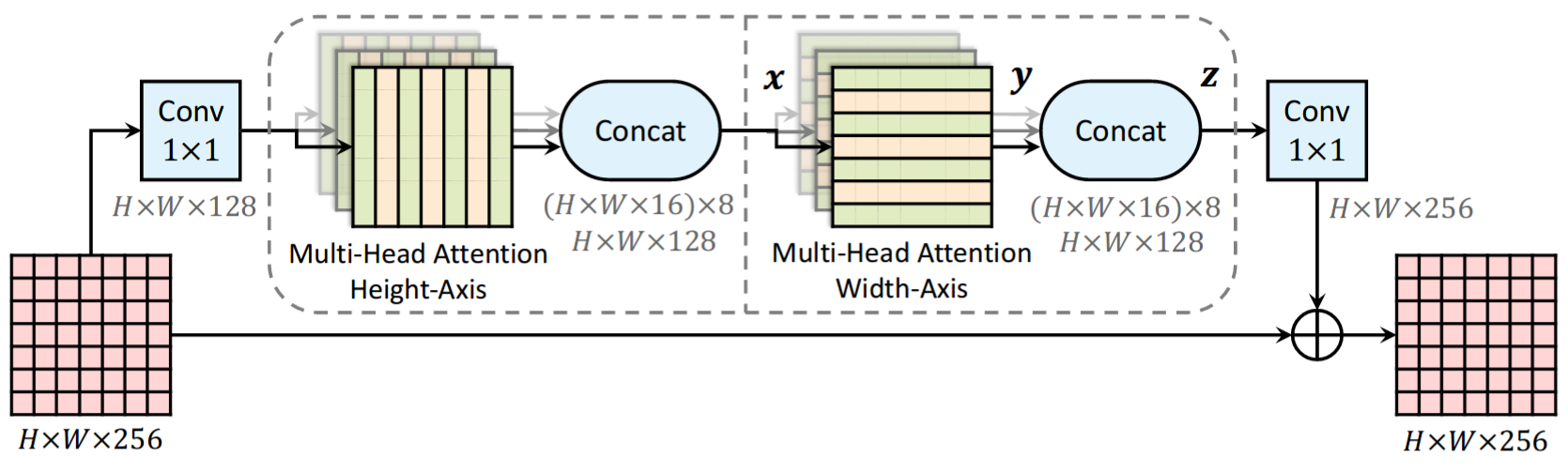
Superpixel Transformers for Efficient Semantic Segmentation
Alex Zihao Zhu, Jieru Mei, Siyuan Qiao, Hang Yan, Yukun Zhu, Liang-Chieh Chen, Henrik Kretzschmar
In International Conference on Intelligent Robots and Systems (IROS), Detroit, Michigan, USA, October 2023
[preprint (arxiv: 2309.16889)]
|
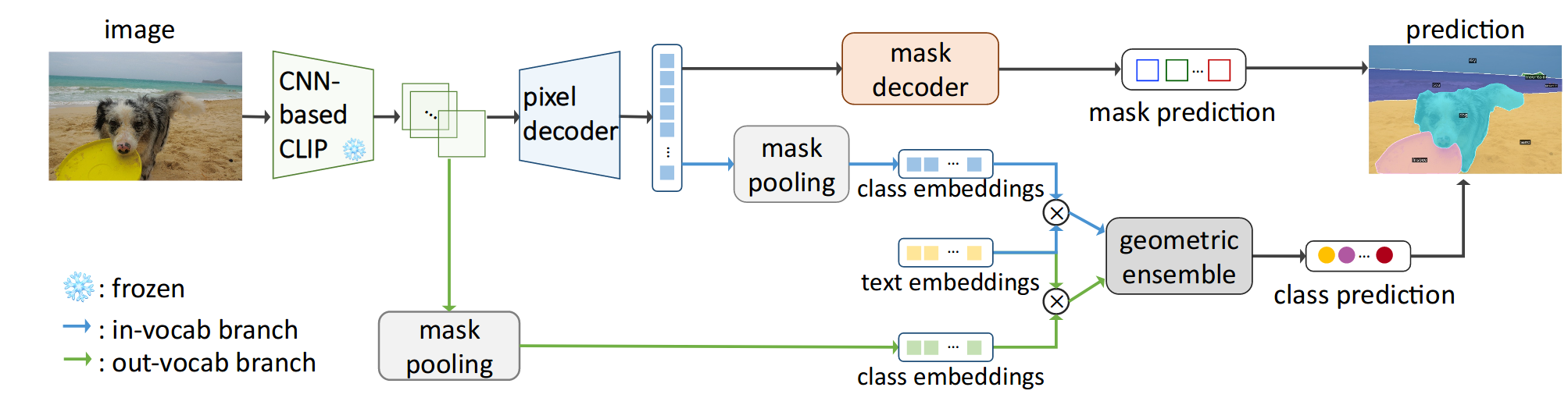 |
Convolutions Die Hard: Open-Vocabulary Segmentation with Single Frozen Convolutional CLIP
Qihang Yu, Ju He, Xueqing Deng, Xiaohui Shen, Liang-Chieh Chen
In Neural Information Processing Systems (NeurIPS), New Orleans, Louisiana, USA, December 2023
[preprint (arxiv: 2308.02487)] [PyTorch code]
|
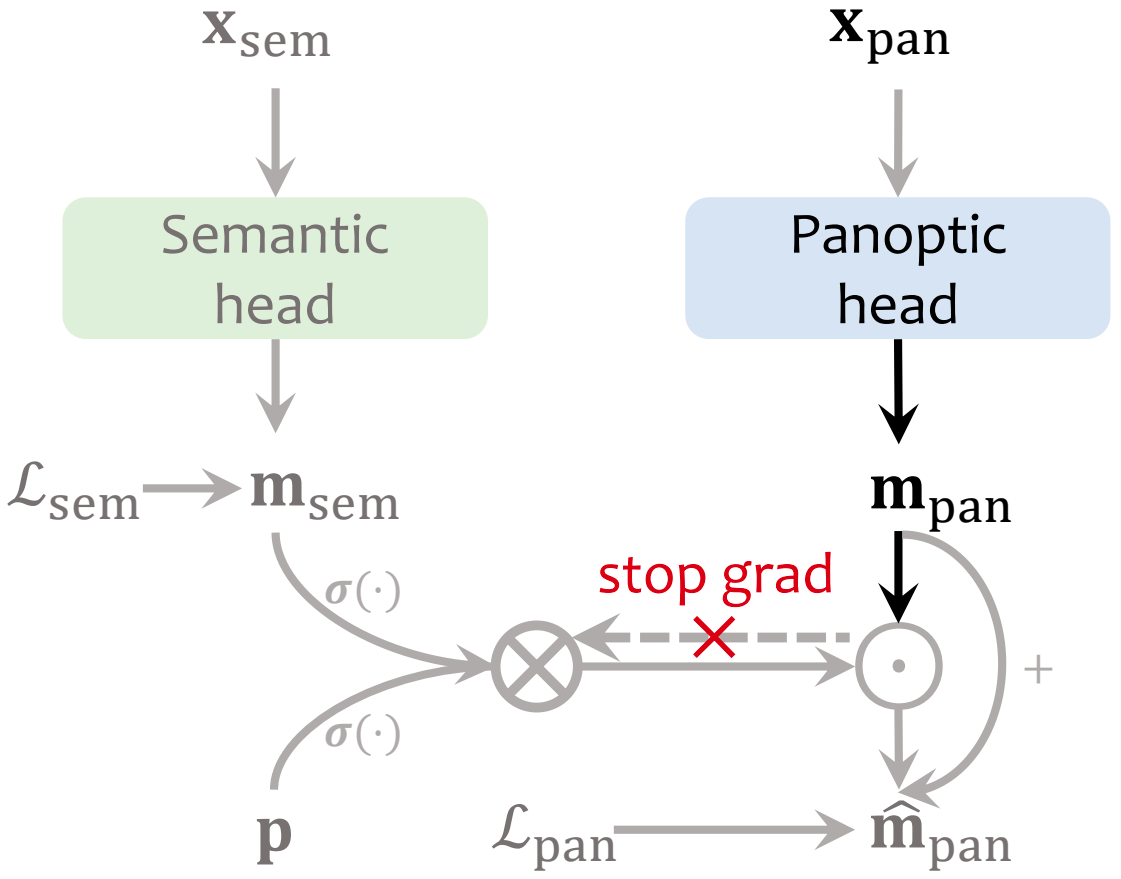 |
ReMaX: Relaxing for Better Training on Efficient Panoptic Segmentation
Shuyang Sun, Weijun Wang, Qihang Yu, Andrew Howard, Philip Torr, Liang-Chieh Chen
In Neural Information Processing Systems (NeurIPS), New Orleans, Louisiana, USA, December 2023
[preprint (arxiv: 2306.17319)]
|
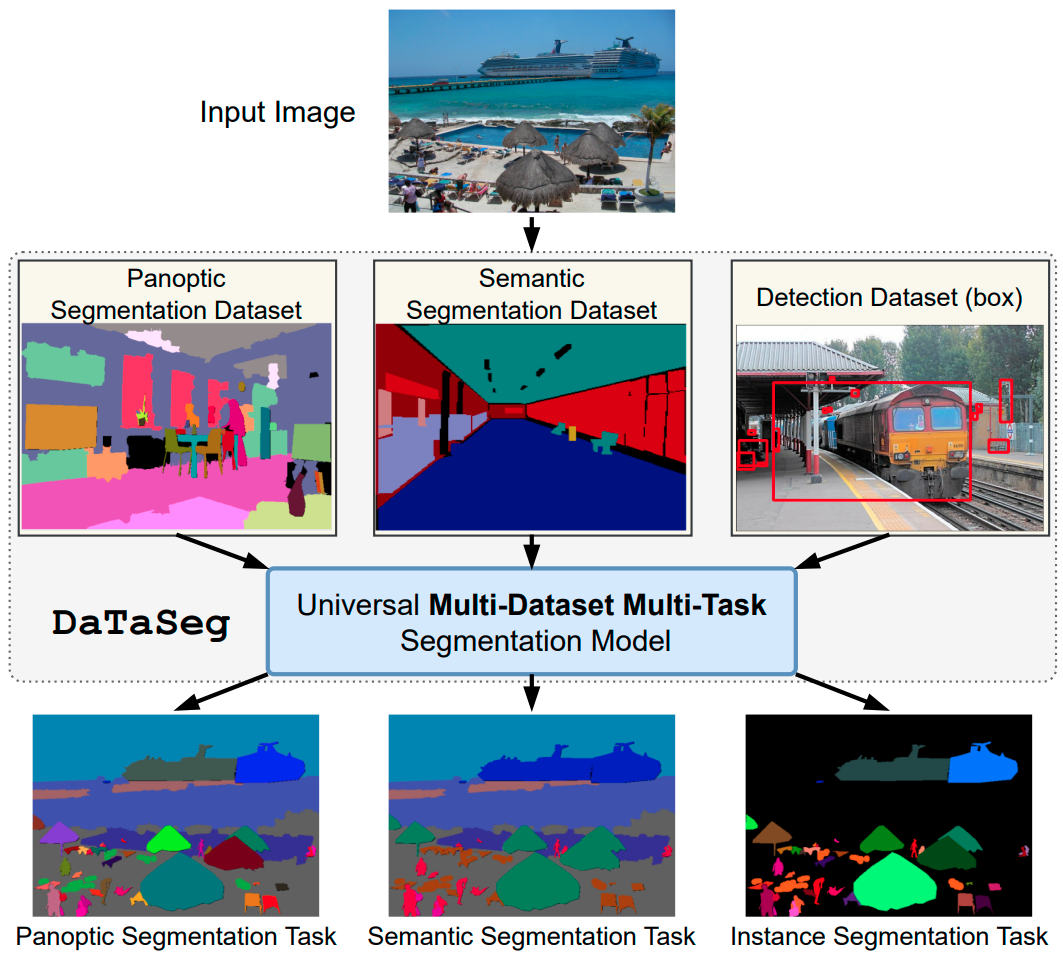 |
DaTaSeg: Taming a Universal Multi-Dataset Multi-Task Segmentation Model
Xiuye Gu, Yin Cui, Jonathan Huang, Abdullah Rashwan, Xuan Yang, Xingyi Zhou, Golnaz Ghiasi, Weicheng Kuo, Huizhong Chen, Liang-Chieh Chen, David Ross
In Neural Information Processing Systems (NeurIPS), New Orleans, Louisiana, USA, December 2023
[preprint (arxiv: 2306.01736)]
|
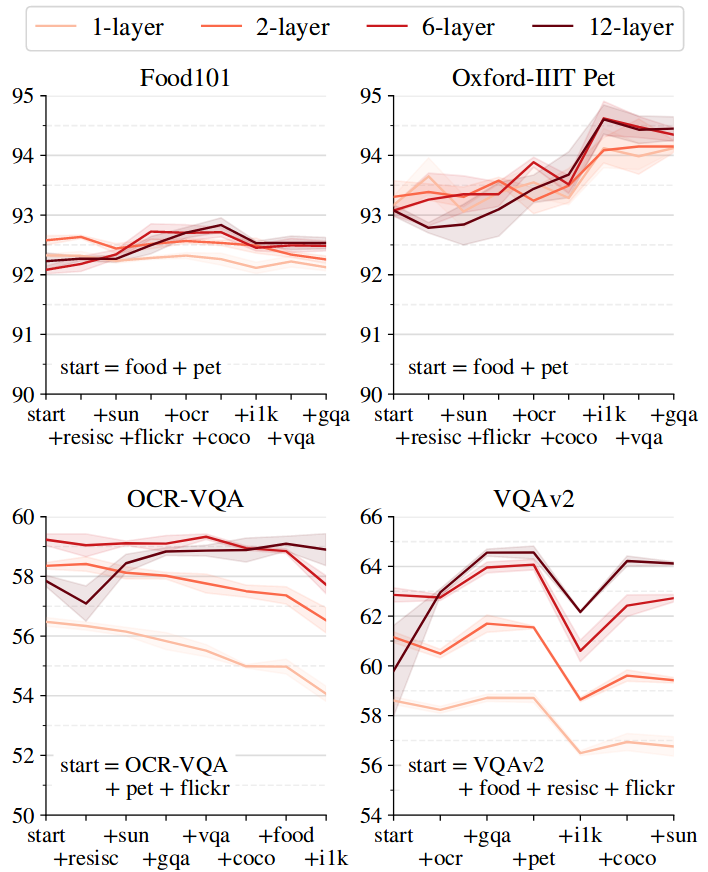 |
A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision
Lucas Beyer, Bo Wan, Gagan Madan, Filip Pavetic, Andreas Steiner, Alexander Kolesnikov, Andre Susano Pinto, Emanuele Bugliarello, Xiao Wang, Qihang Yu, Liang-Chieh Chen, Xiaohua Zhai
Technical report
[preprint (arxiv: 2303.17376)]
|
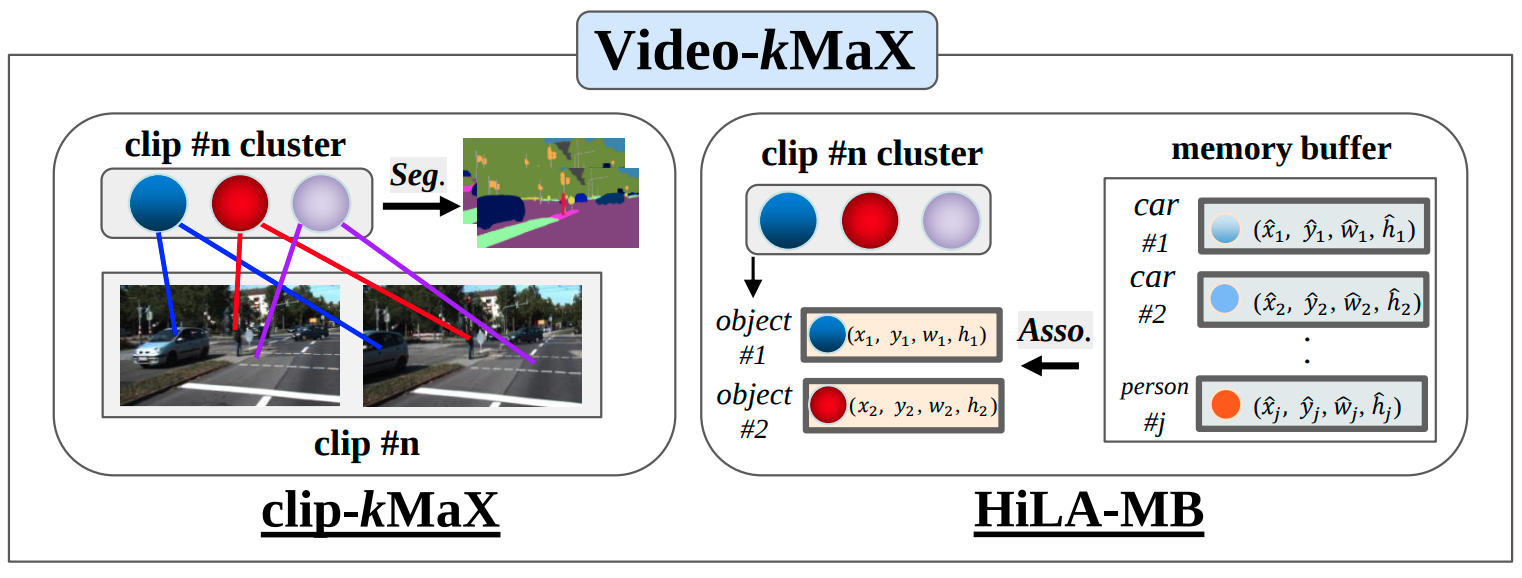 |
Video-kMaX: A Simple Unified Approach for Online and Near-Online Video Panoptic Segmentation (oral)
Inkyu Shin, Dahun Kim, Qihang Yu, Jun Xie, Hong-Seok Kim, Bradley Green, In So Kweon, Kuk-Jin Yoon, Liang-Chieh Chen
Full version appeared in Winter Conference on Applications of Computer Vision (WACV), Waikoloa, Hawaii, USA, January 2024. (oral)
Short version appeared in CVPR 2023 T4V (Transformers for Vision) workshop, Vancouver, Canada, June 2023. (spotlight)
[preprint (arxiv: 2304.04694)]
|
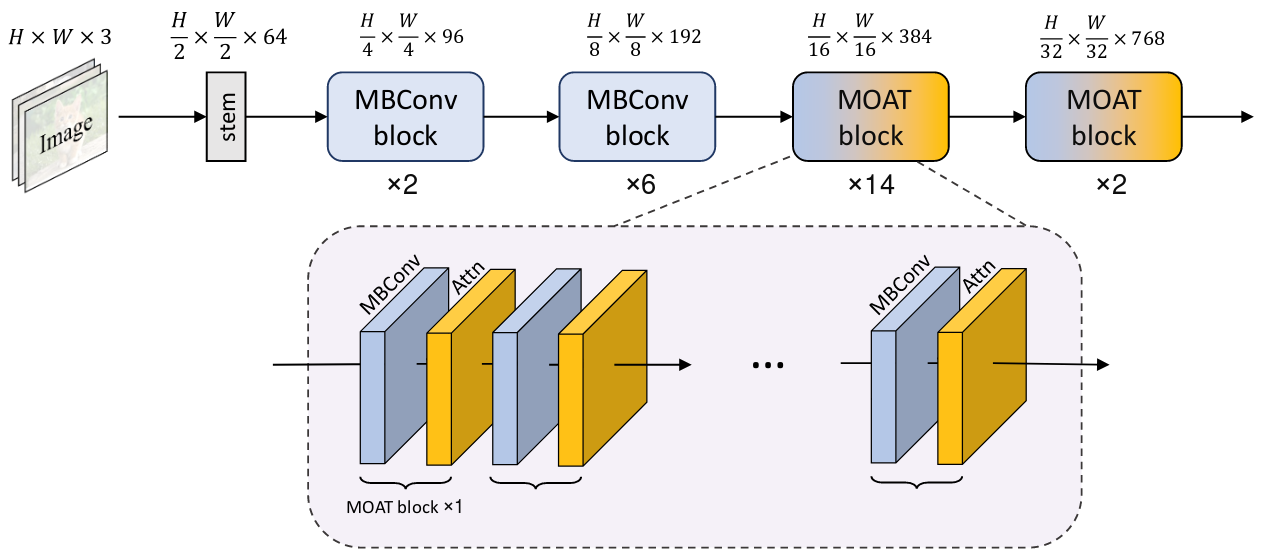 |
MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models
Chenglin Yang, Siyuan Qiao, Qihang Yu, Xiaoding Yuan, Yukun Zhu, Alan Yuille, Hartwig Adam, Liang-Chieh Chen
In International Conference on Learning Representations (ICLR), Kigali, Rwanda, May 2023.
[preprint (arxiv: 2210.01820)] [code]
|
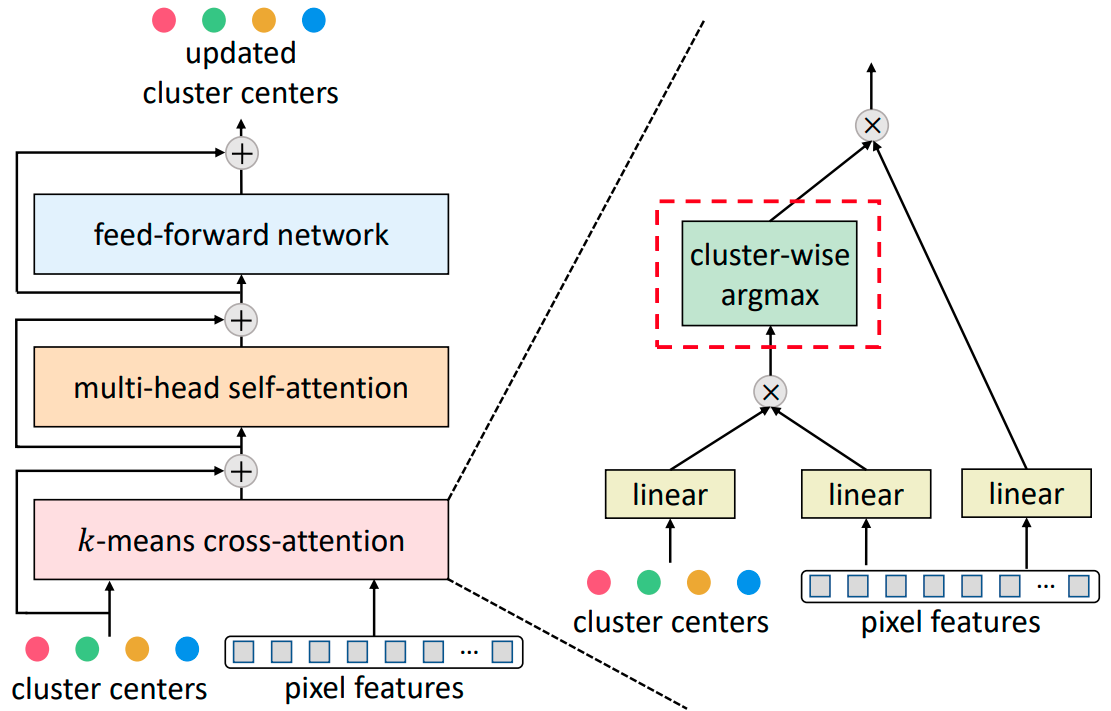 |
k-means Mask Transformer
Qihang Yu, Huiyu Wang, Siyuan Qiao, Maxwell Collins, Yukun Zhu, Hartwig Adam, Alan Yuille, Liang-Chieh Chen
In European Conference on Computer Vision (ECCV), Tel Aviv, Israel, October 2022.
[preprint (arxiv: 2207.04044)] [TensorFlow2 code] [Google AI Blog post] [PyTroch code]
|
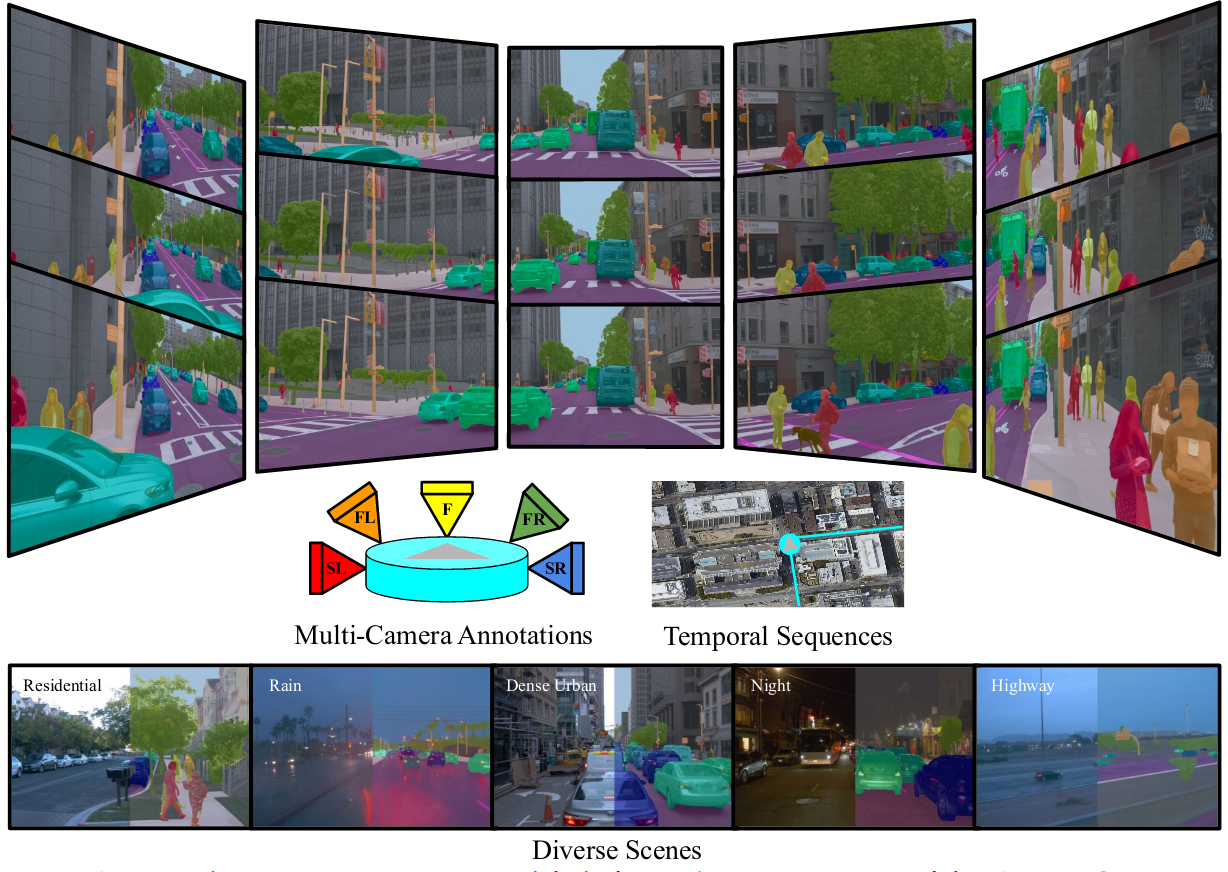 |
Waymo Open Dataset: Panoramic Video Panoptic Segmentation
Jieru Mei, Alex Zihao Zhu, Xinchen Yan, Hang Yan, Siyuan Qiao, Yukun Zhu, Liang-Chieh Chen, Henrik Kretzschmar, Dragomir Anguelov
In European Conference on Computer Vision (ECCV), Tel Aviv, Israel, October 2022.
[preprint (arxiv: 2206.07704)] [dataset]
|
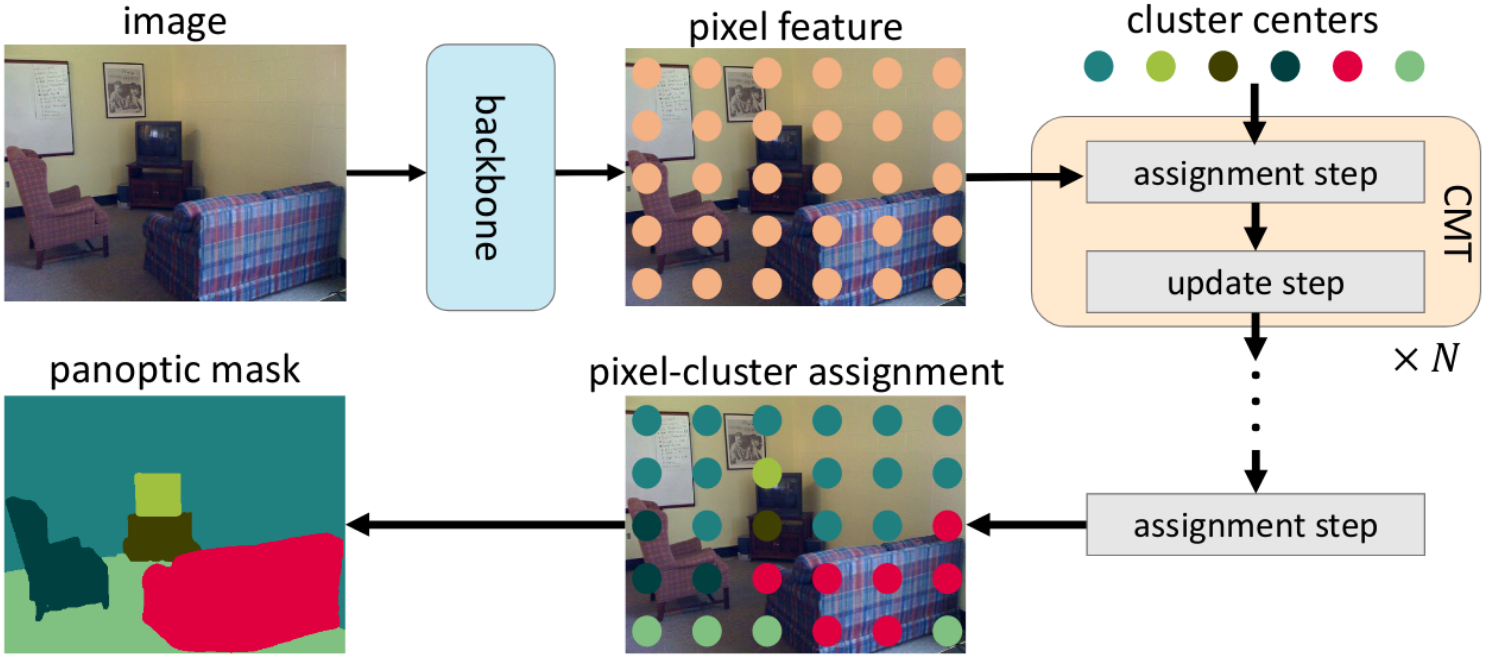 |
CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation (oral)
Qihang Yu, Huiyu Wang, Dahun Kim, Siyuan Qiao, Maxwell Collins, Yukun Zhu, Hartwig Adam, Alan Yuille, Liang-Chieh Chen
In Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, Louisiana, USA, June 2022.
[preprint (arxiv: 2206.08948)] [talk]
|
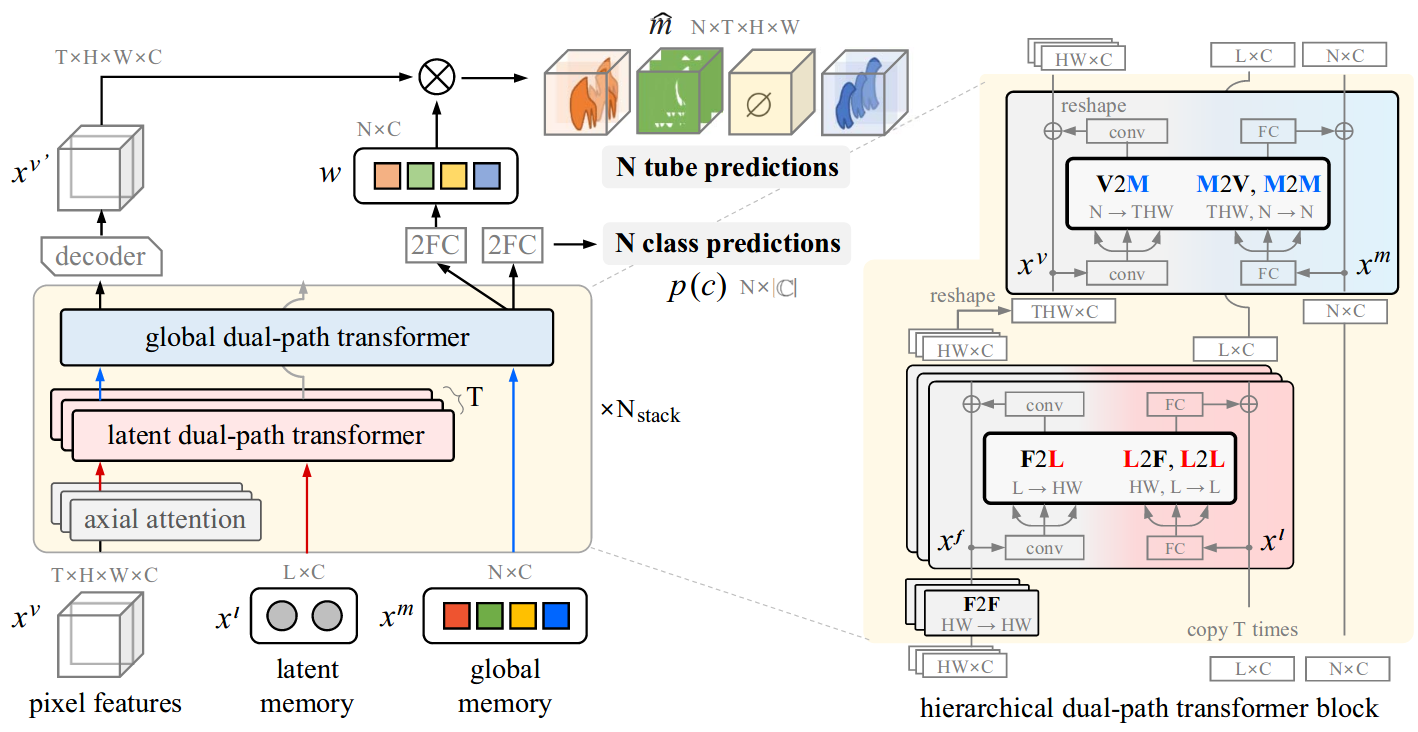 |
TubeFormer-DeepLab: Video Mask Transformer
Dahun Kim, Jun Xie, Huiyu Wang, Siyuan Qiao, Qihang Yu, Hong-Seok Kim, Hartwig Adam, In So Kweon, Liang-Chieh Chen
In Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, Louisiana, USA, June 2022.
[preprint (arxiv: 2205.15361)] [video-prediction-results]
|
 |
DeepLab2: A TensorFlow Library for Deep Labeling
Mark Weber*, Huiyu Wang*, Siyuan Qiao*, Jun Xie, Maxwell Collins, Yukun Zhu, Liangzhe Yuan, Dahun Kim, Qihang Yu,
Daniel Cremers, Laura Leal-Taixe, Alan Yuille, Florian Schroff, Hartwig Adam, Liang-Chieh Chen
(*equal contribution)
Technical report
[preprint (arxiv: 2106.09748)] [DeepLab2 code] [Talk at ICCV 2021 VSPW workshop]
|
 |
STEP: Segmenting and Tracking Every Pixel
Mark Weber, Jun Xie, Maxwell Collins, Yukun Zhu, Paul Voigtlaender, Hartwig Adam, Bradley Green, Andreas Geiger,
Bastian Leibe, Daniel Cremers, Aljosa Osep, Laura Leal-Taixe, Liang-Chieh Chen
In Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks, Virtual, December 2021.
[preprint (arxiv: 2102.11859)] [DeepLab2 code] [STQ numpy code] [KITTI-STEP] [MOTChallenge-STEP]
|
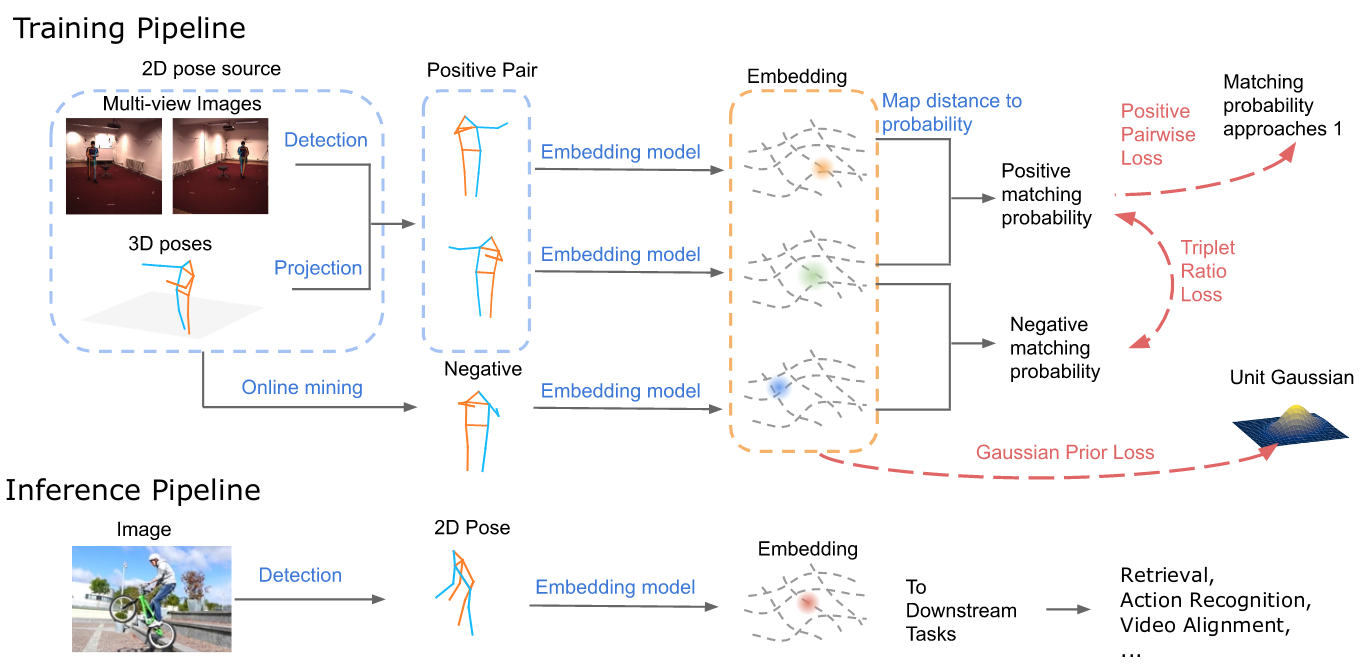 |
View-Invariant, Occlusion-Robust Probabilistic Embedding for Human Pose
Ting Liu, Jennifer J. Sun, Long Zhao, Jiaping Zhao, Liangzhe Yuan, Yuxiao Wang, Liang-Chieh Chen, Florian Schroff, Hartwig Adam
International Journal of Computer Vision (IJCV)
[preprint (arxiv: 2010.13321)]
|
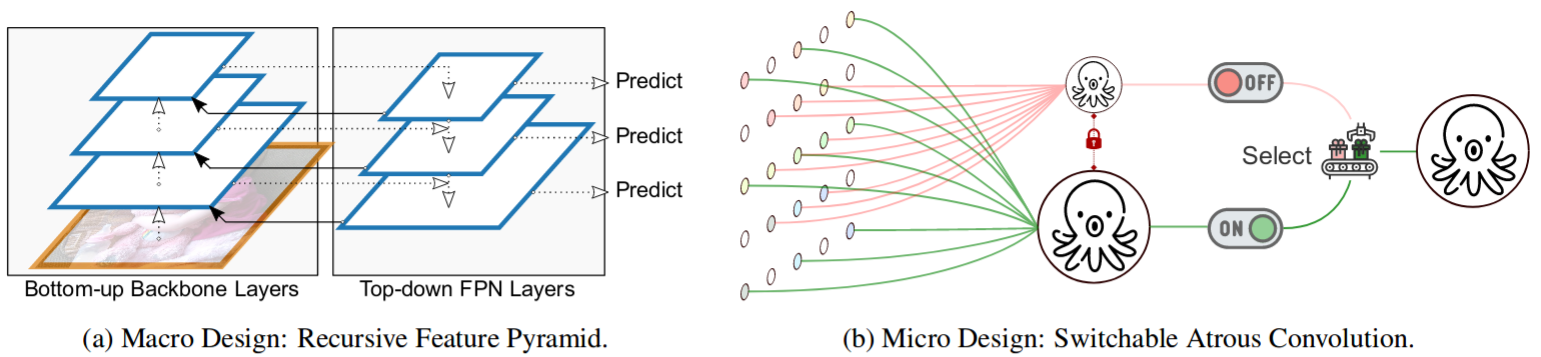 |
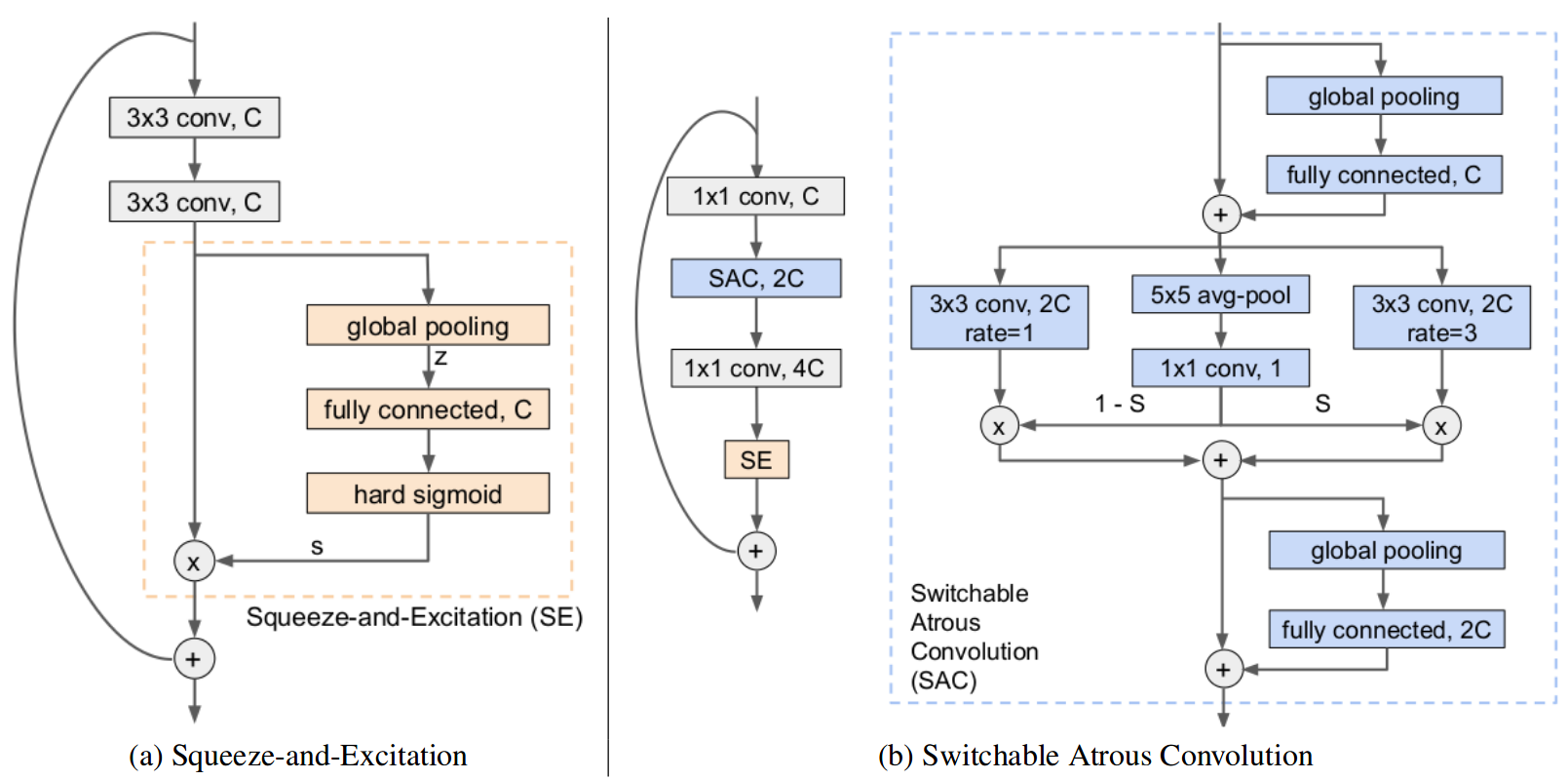
DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
Siyuan Qiao, Liang-Chieh Chen, Alan Yuille
In Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, June 2021.
[preprint (arxiv: 2006.02334)] [code]
|
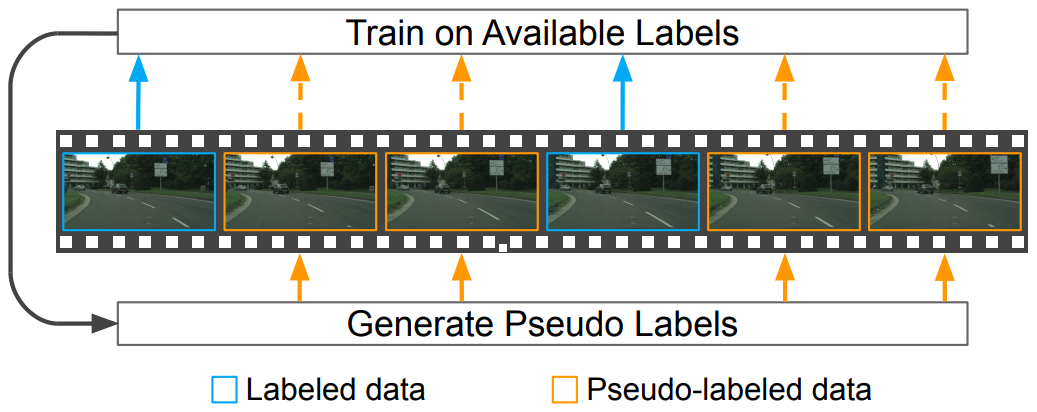 |
Naive-Student: Leveraging Semi-Supervised Learning in Video Sequences for Urban Scene Segmentation
Liang-Chieh Chen, Raphael Gontijo Lopes, Bowen Cheng, Maxwell D. Collins, Ekin D. Cubuk, Barret Zoph, Hartwig Adam, Jonathon Shlens
In European Conference on Computer Vision (ECCV), Glasgow, United Kingdom (Virtual), August 2020.
[preprint (arxiv: 2005.10266)]
|
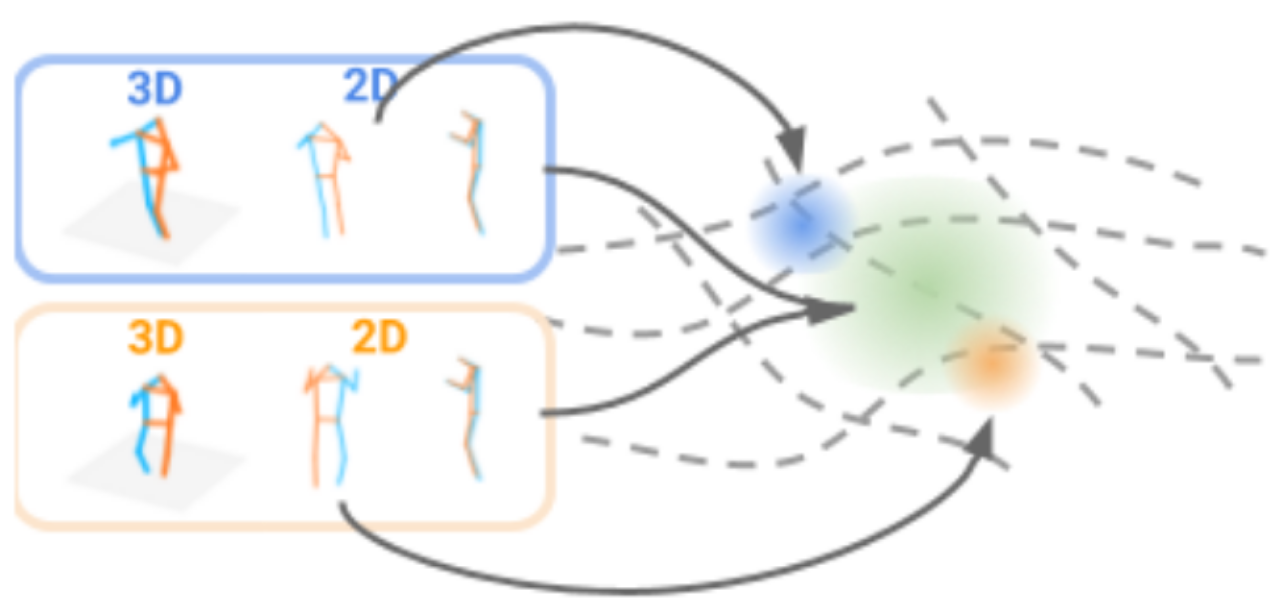 |
View-Invariant Probabilistic Embedding for Human Pose (spotlight)
Jennifer J. Sun, Jiaping Zhao, Liang-Chieh Chen, Florian Schroff, Hartwig Adam, Ting Liu
In European Conference on Computer Vision (ECCV), Glasgow, United Kingdom (Virtual), August 2020.
[preprint (arxiv: 1912.01001)] [Google AI Blog post]
|
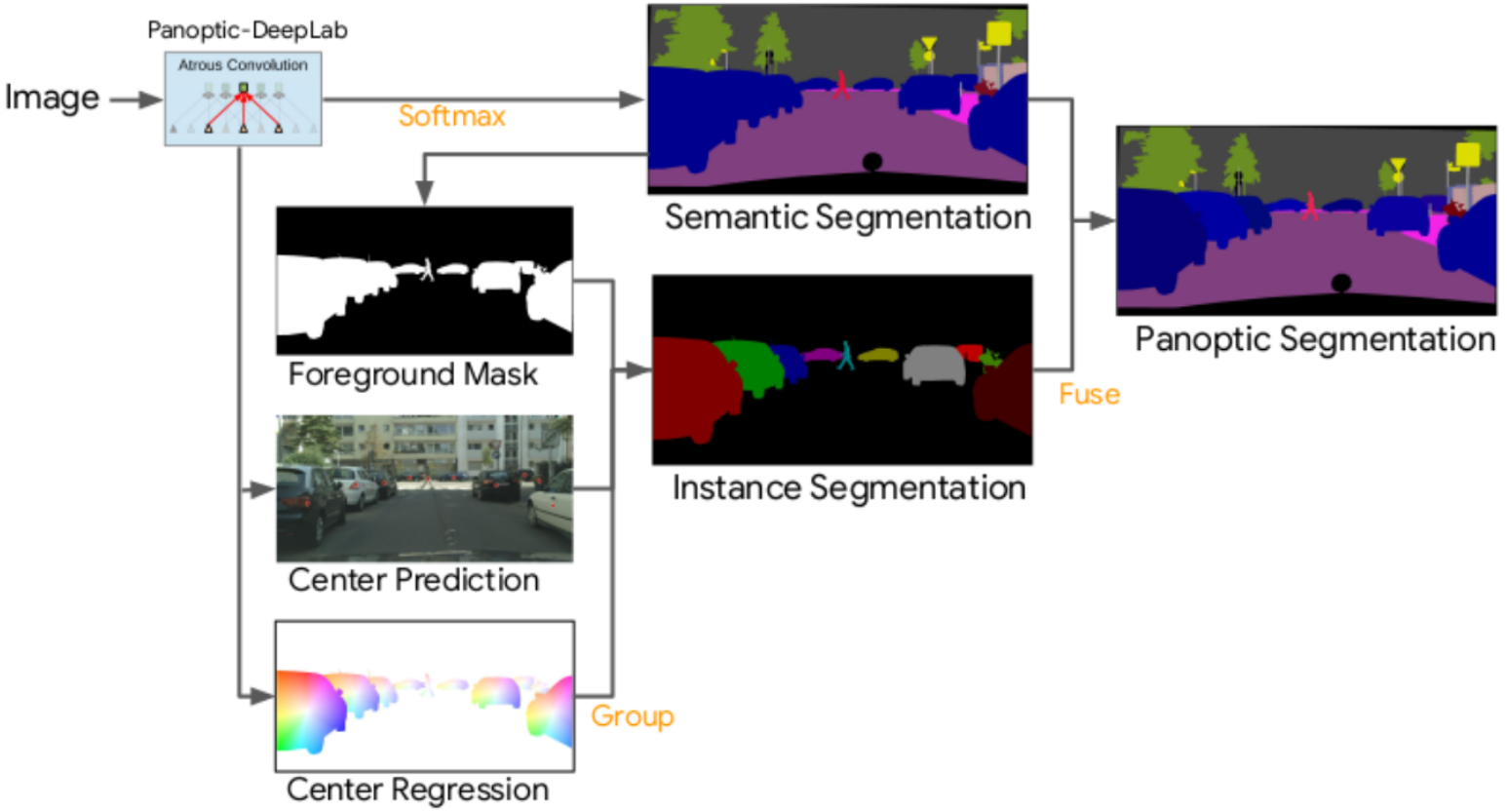 |
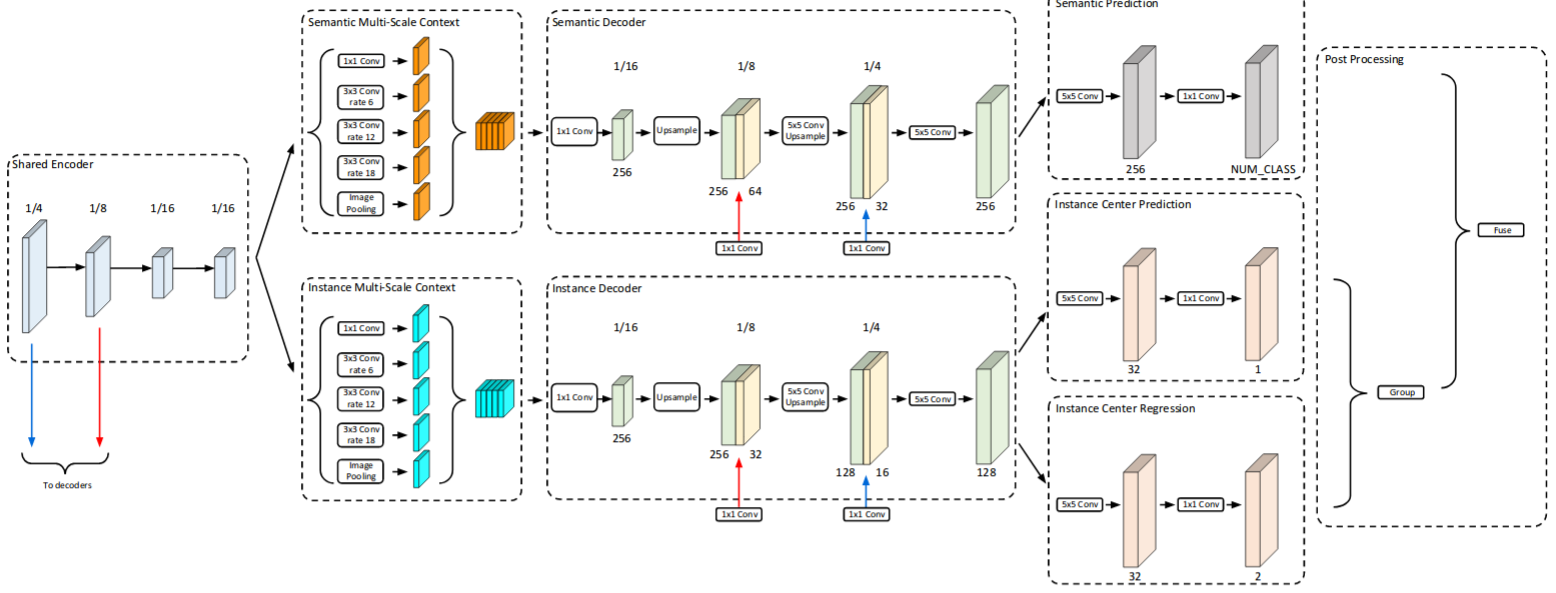
Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation
Bowen Cheng, Maxwell D. Collins, Yukun Zhu, Ting Liu, Thomas S. Huang, Hartwig Adam, Liang-Chieh Chen
In Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, June 2020.
[preprint (arxiv: 1911.10194)] [unofficial PyTorch re-implementation] [Detectron2/projects/Panoptic-DeepLab (unofficial re-implementation)]
[DeepLab2 code (official implementation)] [Google AI-Blog post]
|
 |
Panoptic-DeepLab
Bowen Cheng, Maxwell D. Collins, Yukun Zhu, Ting Liu, Thomas S. Huang, Hartwig Adam, Liang-Chieh Chen
In ICCV 2019 Joint COCO and Mapillary Recognition Challenge Workshop.
Best result, best paper and most innovative awards on Mapillary Vistas Panoptic Segmentation track.
[preprint (arxiv: 1910.04751)]
|
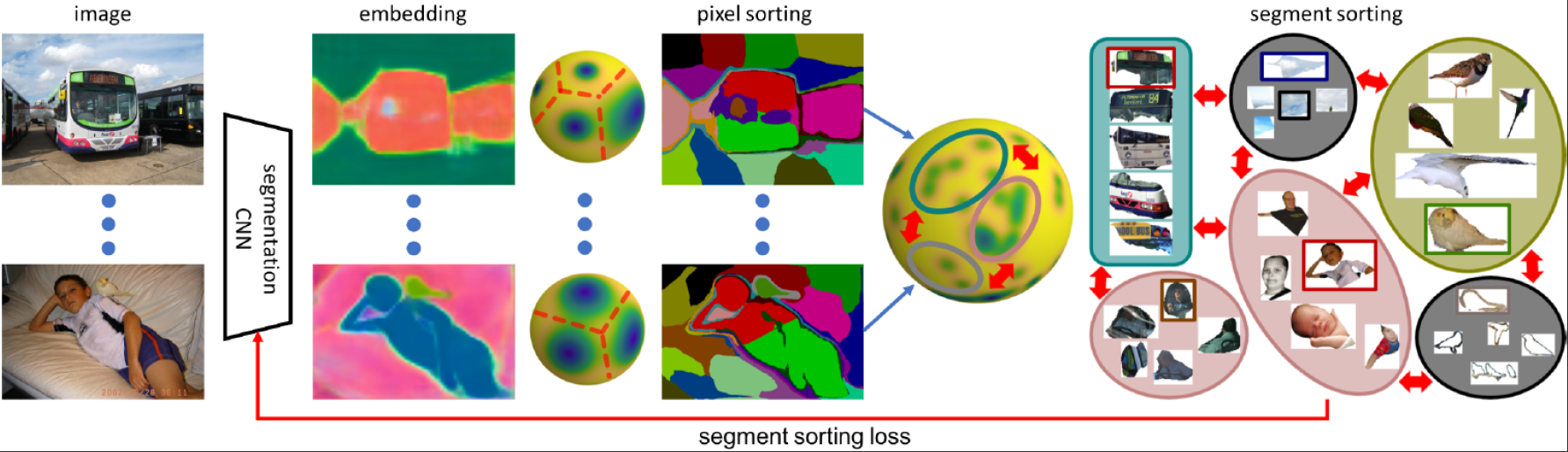 |
SegSort: Segmentation by Discriminative Sorting of Segments
Jyh-Jing Hwang, Stella X. Yu, Jianbo Shi, Maxwell Collins, Tien-Ju Yang, Xiao Zhang, Liang-Chieh Chen
In International Conference on Computer Vision (ICCV), Seoul, South Korea, October 2019.
[preprint (arxiv: 1910.06962)] [website and code]
|
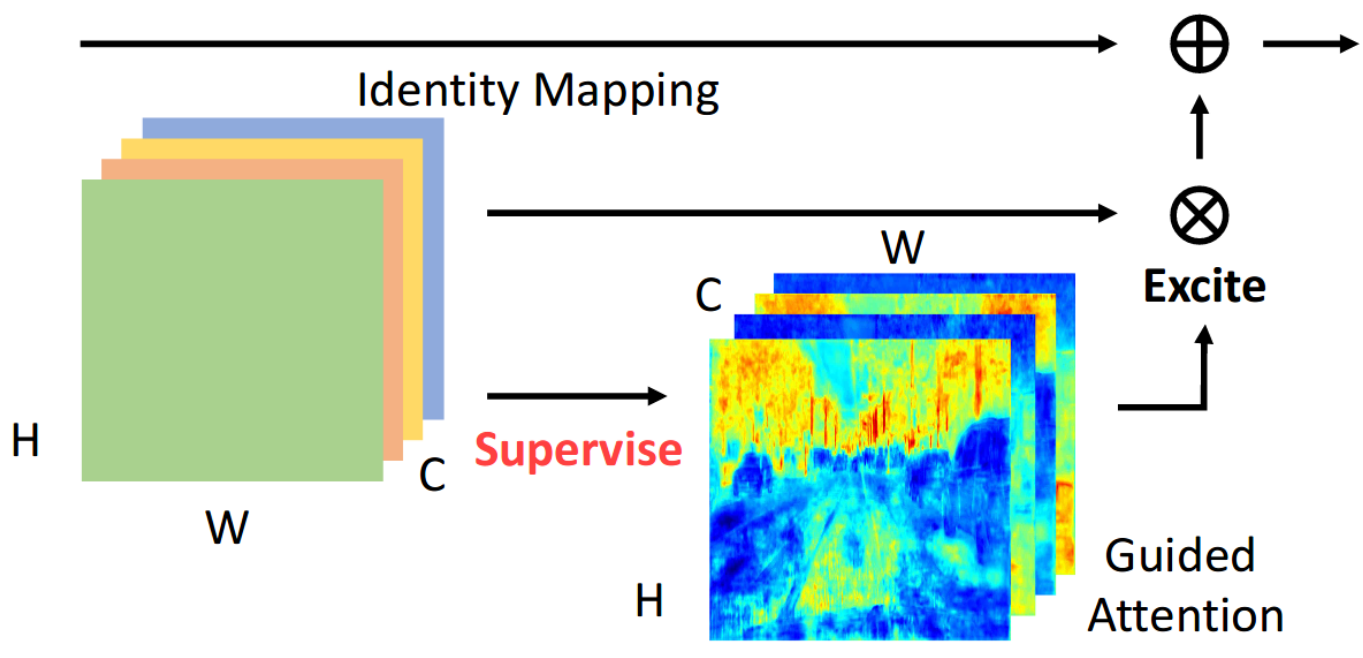 |
SPGNet: Semantic Prediction Guidance for Scene Parsing
Bowen Cheng, Liang-Chieh Chen, Yunchao Wei, Yukun Zhu, Zilong Huang, Jinjun Xiong, Thomas Huang, Wen-Mei Hwu, Honghui Shi
In International Conference on Computer Vision (ICCV), Seoul, South Korea, October 2019.
[preprint (arxiv: 1908.09798)]
|
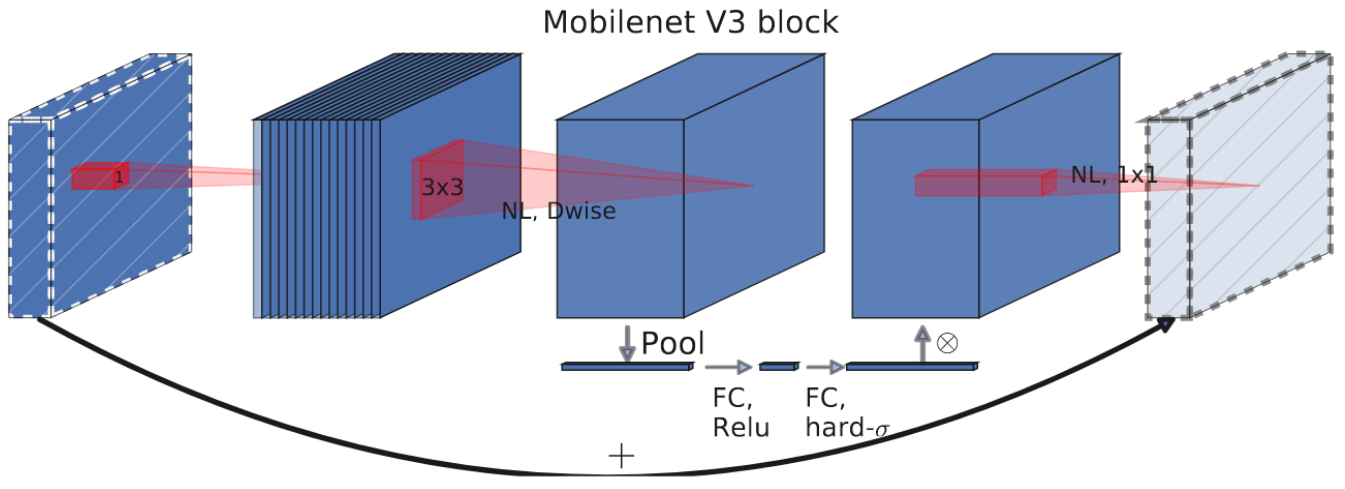 |
Searching for MobileNetV3 (oral)
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam
In International Conference on Computer Vision (ICCV), Seoul, South Korea, October 2019.
[preprint (arxiv: 1905.02244)] [code for (image classification), (object detection), and (semantic segmentation)] [Google AI Blog post]
|
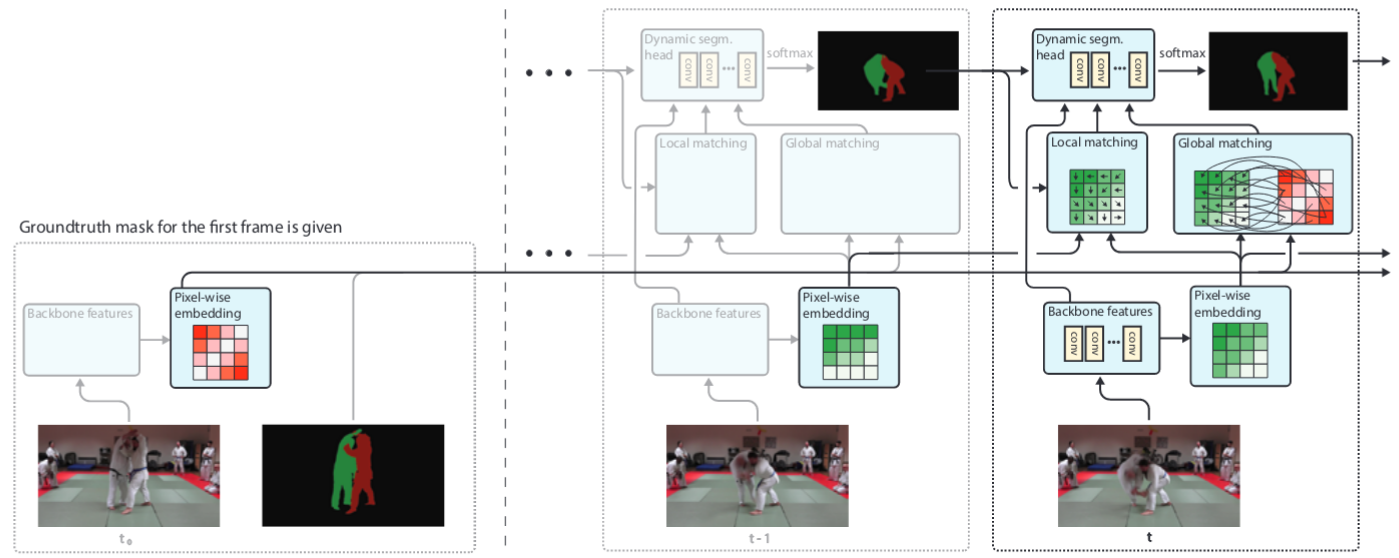 |
FEELVOS: Fast End-to-End Embedding Learning for Video Object
Segmentation
Paul Voigtlaender, Yuning Chai, Florian Schroff, Hartwig Adam, Bastian
Leibe, Liang-Chieh Chen
In Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, California, USA, June 2019.
[preprint (arxiv: 1902.09513)] [code]
|
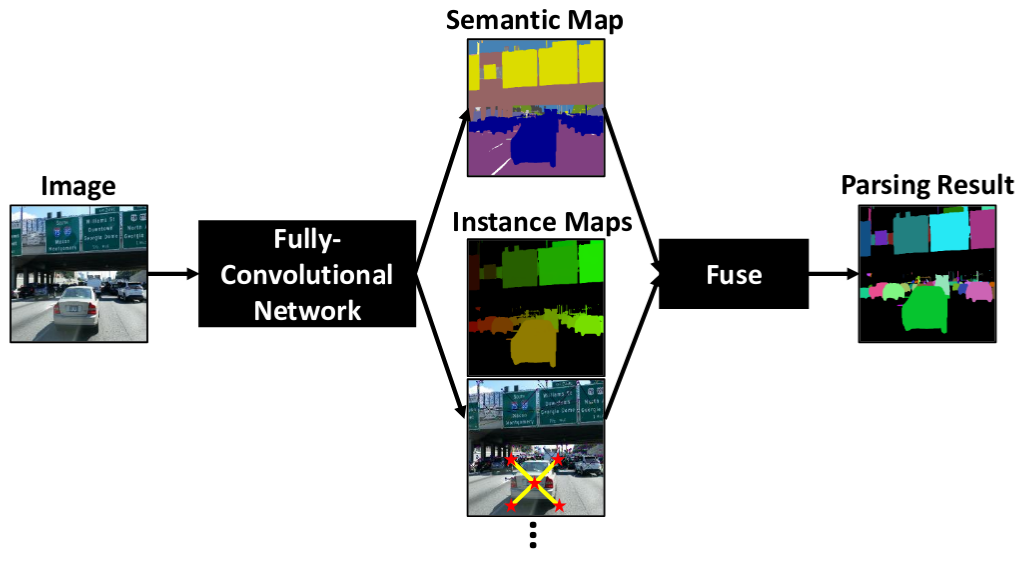 |
DeeperLab: Single-Shot Image Parser
Tien-Ju Yang, Maxwell D. Collins, Yukun Zhu, Jyh-Jing Hwang, Ting Liu, Xiao Zhang, Vivienne Sze, George Papandreou, Liang-Chieh Chen
Technical report
[preprint (arxiv: 1902.05093)] [evaluation code]
|
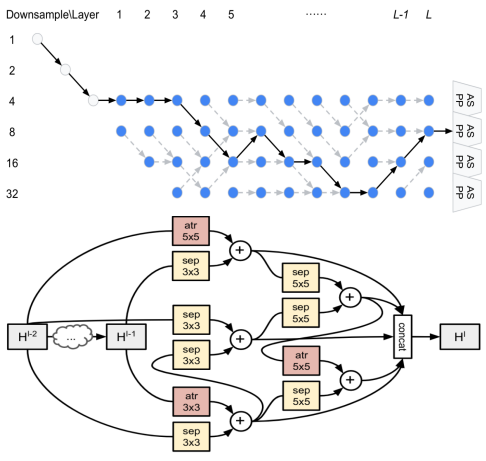 |
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation (oral)
Chenxi Liu, Liang-Chieh Chen, Florian Schroff, Hartwig Adam, Wei Hua, Alan Yuille, Li Fei-Fei
In Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, California, USA, June 2019.
[preprint (arxiv: 1901.02985)] [code]
|
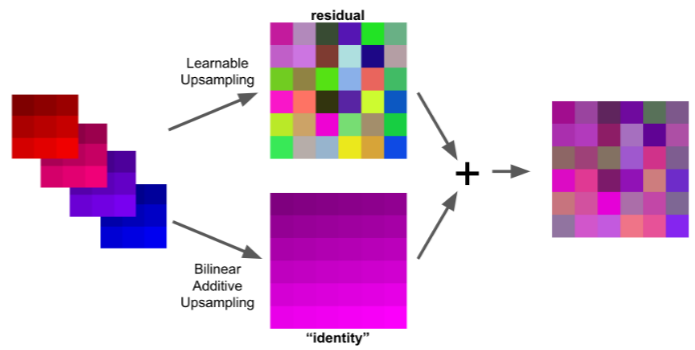 |
The Devil is in the Decoder: Classification, Regression and GANs
Zbigniew Wojna, Vittorio Ferrari, Sergio Guadarrama, Nathan Silberman, Liang-Chieh Chen, Alireza Fathi, Jasper Uijlings
International Journal of Computer Vision (IJCV)
[preprint (arxiv: 1707.05847)]
|
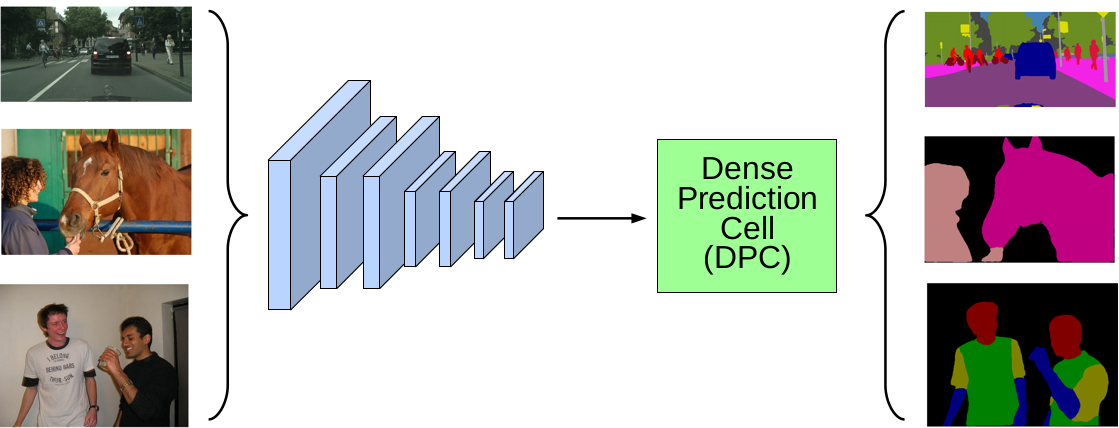 |
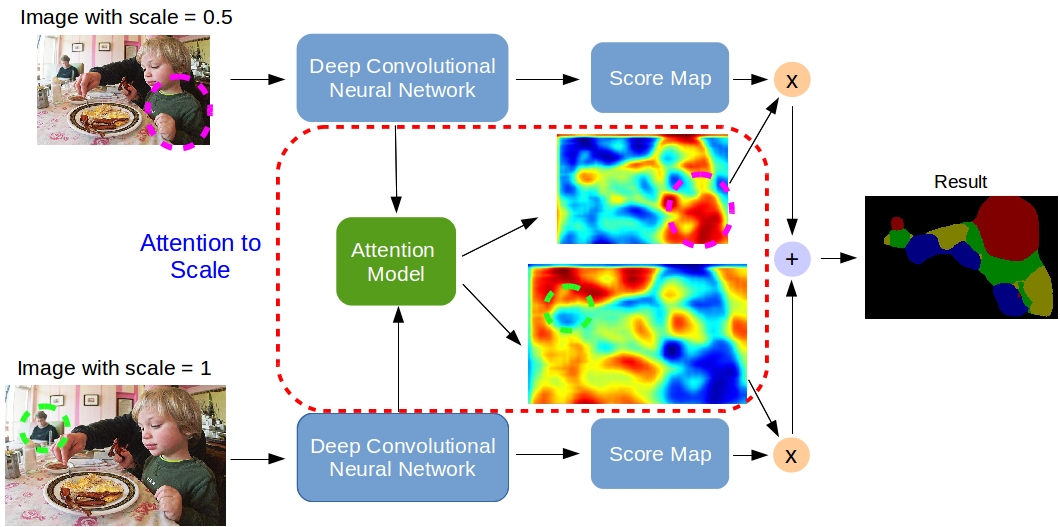
Searching for Efficient Multi-Scale Architectures for Dense Image
Prediction
Liang-Chieh Chen, Maxwell D. Collins, Yukun Zhu, George Papandreou,
Barret Zoph, Florian Schroff, Hartwig Adam, Jonathon Shlens
In Neural Information Processing Systems (NeurIPS), Montréal, Canada, December 2018.
[preprint (arxiv: 1809.04184)] [code] [poster]
|
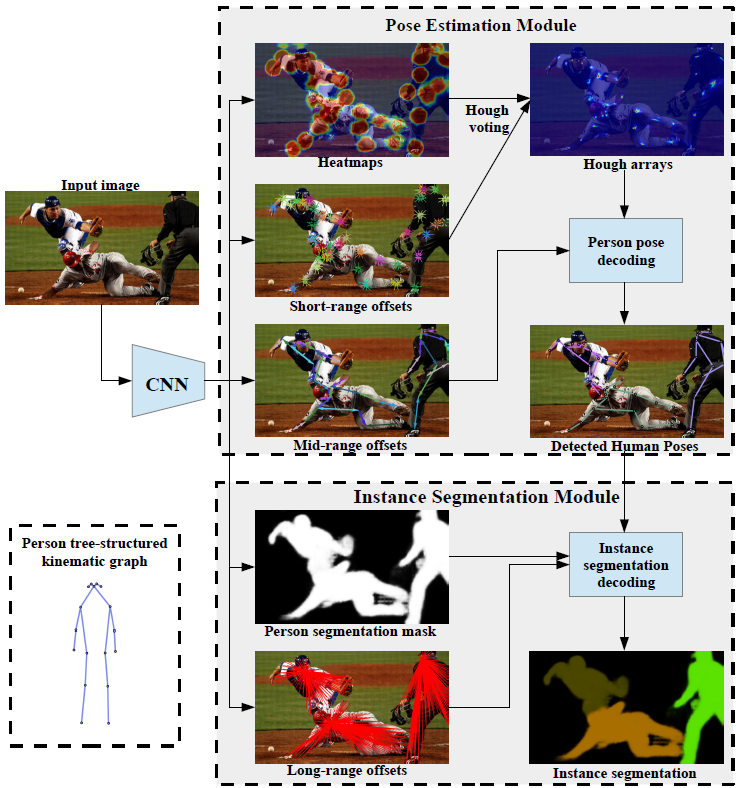 |
PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
George Papandreou, Tyler Zhu, Liang-Chieh Chen, Spyros Gidaris, Jonathan Tompson, Kevin Murphy
In European Conference on Computer Vision (ECCV), Munich, Germany, September 2018.
[preprint (arxiv: 1803.08225)]
|
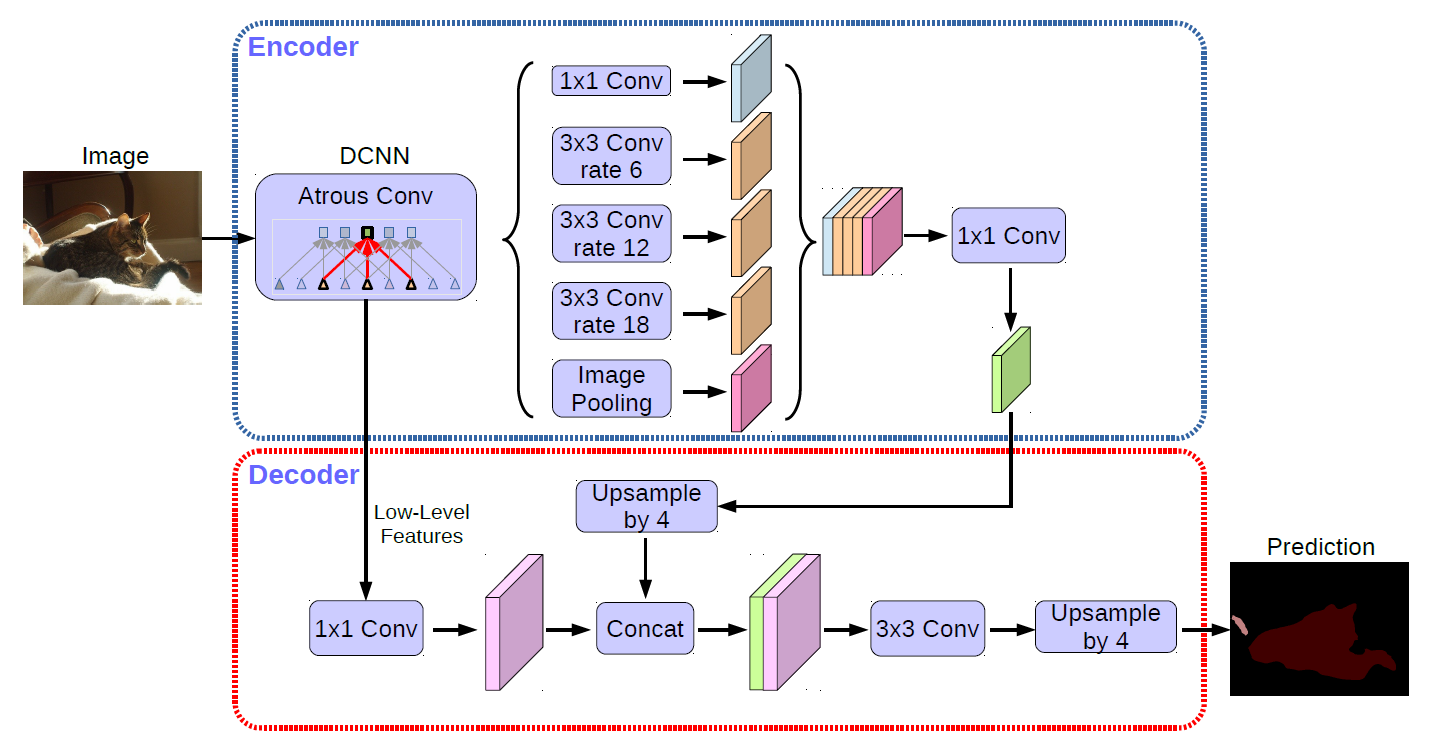 |
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam
In European Conference on Computer Vision (ECCV), Munich, Germany, September 2018.
[preprint (arxiv: 1802.02611)] [code] [Google AI Blog post]
|
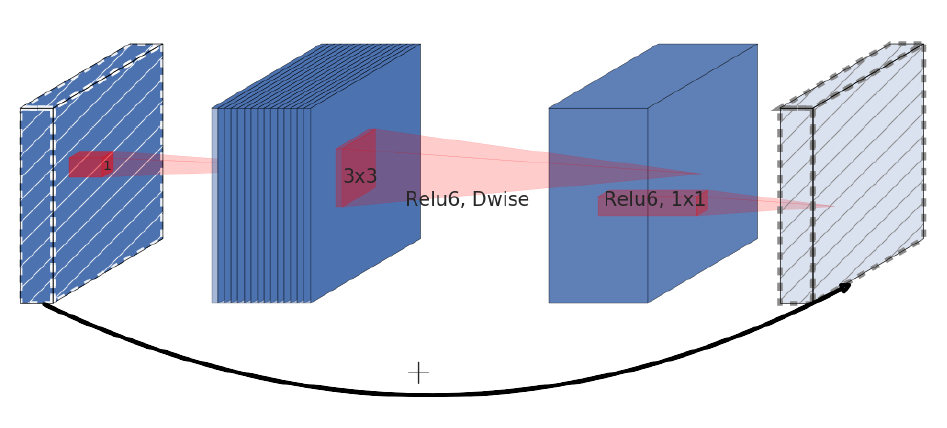 |
MobileNetV2: Inverted Residuals and Linear Bottlenecks
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
In Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, Utah, USA, June 2018.
[preprint (arxiv: 1801.04381)] [code] [Google AI Blog post]
|
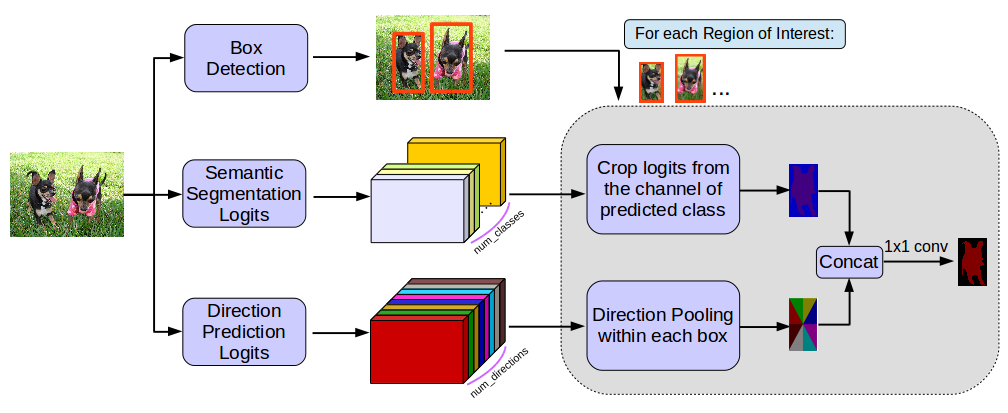 |
MaskLab: Instance Segmentation by Refining Object Detection with Semantic
and Direction Features
Liang-Chieh Chen, Alexander Hermans, George Papandreou, Florian Schroff, Peng Wang, Hartwig Adam
In Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, Utah, USA, June 2018.
[preprint (arxiv: 1712.04837)]
|
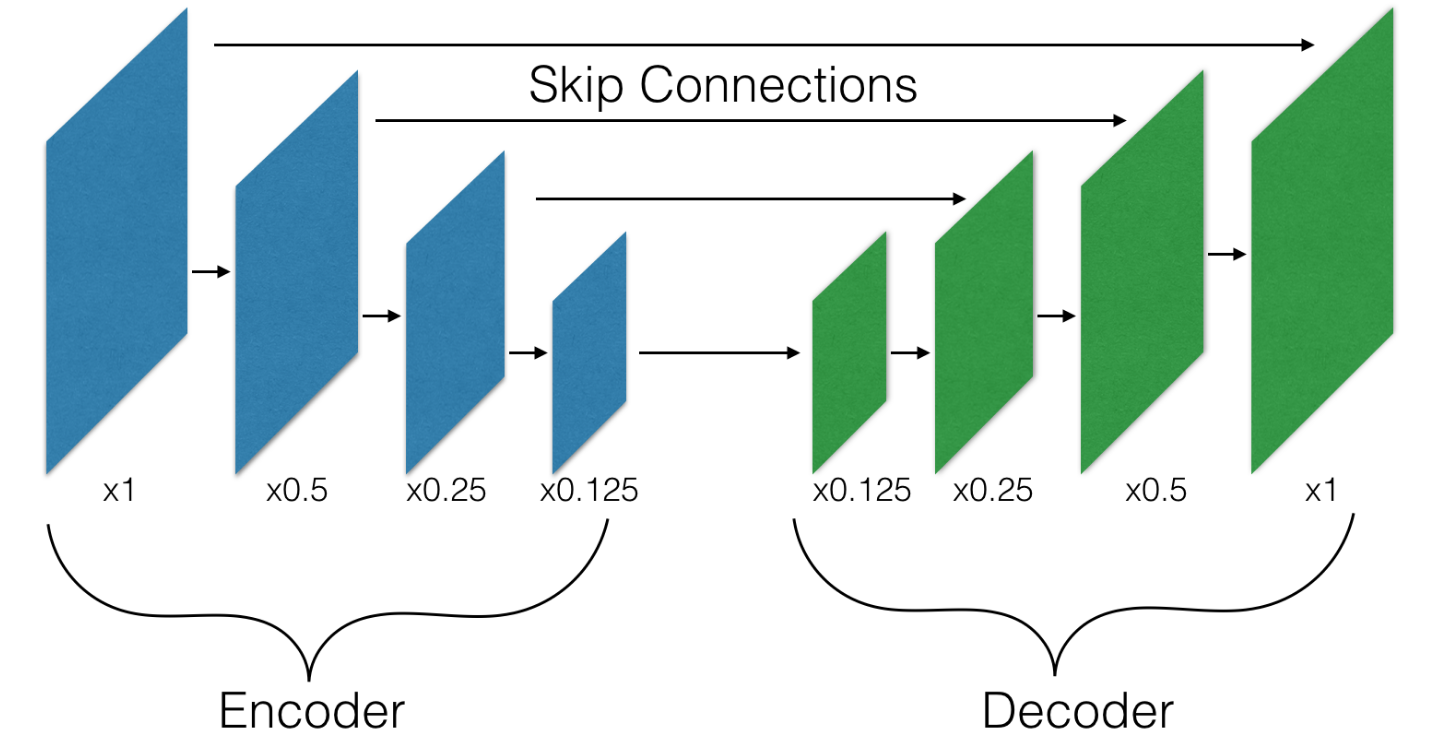 |
The Devil is in the Decoder
Zbigniew Wojna, Vittorio Ferrari, Sergio Guadarrama, Nathan Silberman, Liang-Chieh Chen, Alireza Fathi, Jasper Uijlings
In British Machine Vision Conference (BMVC), Imperial College London, September 2017.
[preprint (arxiv: 1707.05847)]
|
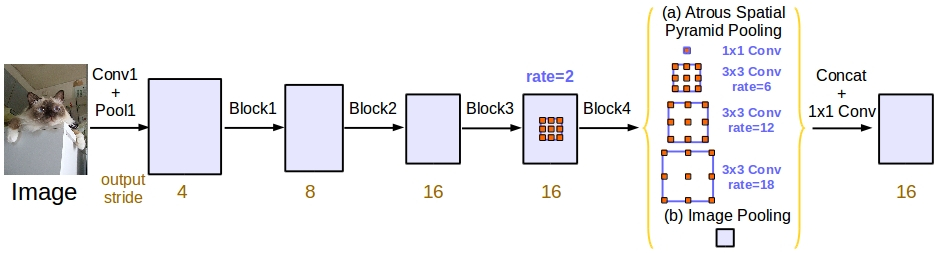 |
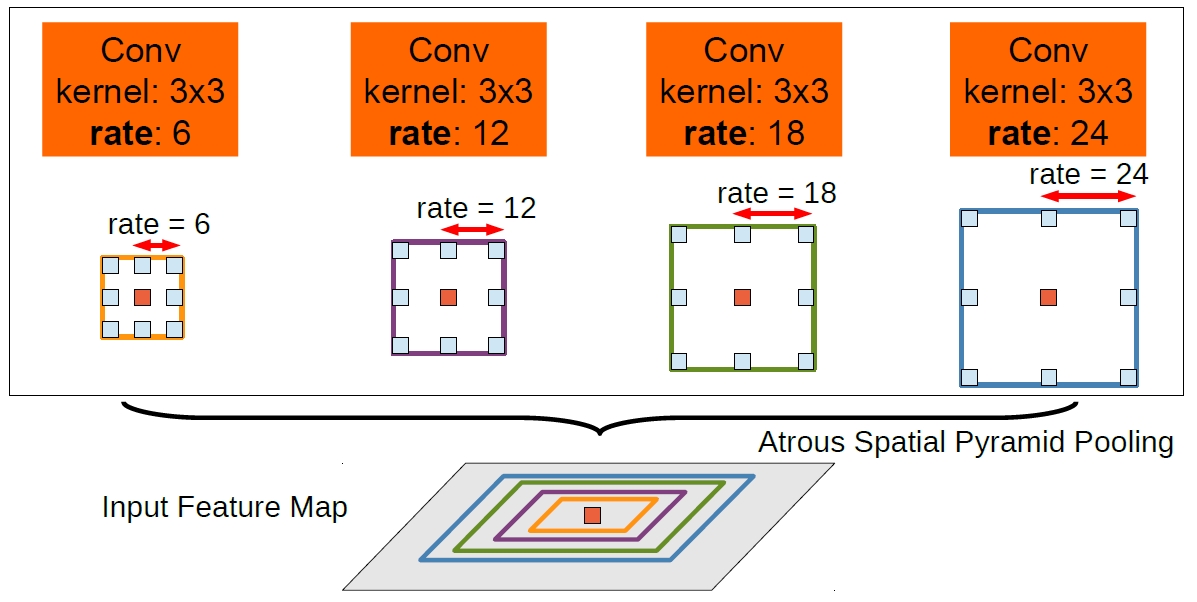
Rethinking Atrous Convolution for Semantic Image Segmentation
Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam
Technical report
[preprint (arxiv: 1706.05587)] [code]
|
 |
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Liang-Chieh Chen*, George Papandreou*, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille (*equal contribution)
Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
[preprint (arxiv: 1606.00915)] [project] [code]
|
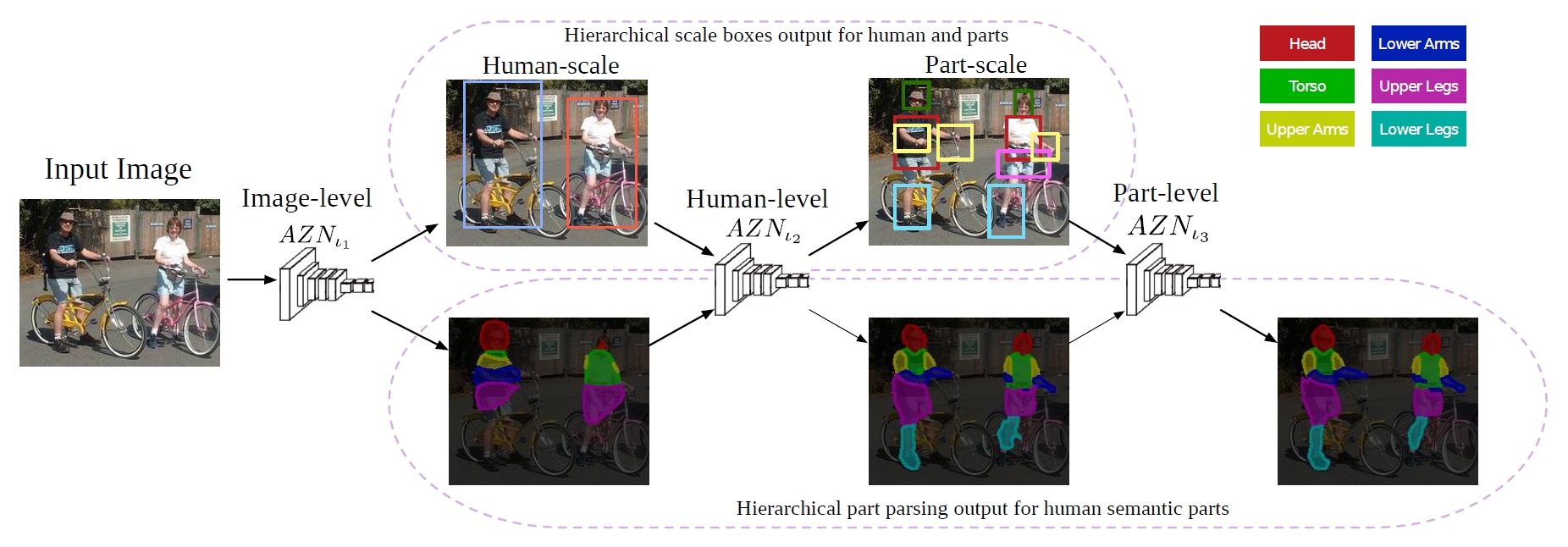 |
Zoom Better to See Clearer: Human Part Segmentation with Auto Zoom Net
Fangting Xia, Peng Wang, Liang-Chieh Chen, Alan L. Yuille
In European Conference on Computer Vision (ECCV), Amsterdam, Netherlands, October 2016.
[preprint (arxiv: 1511.06881)]
|
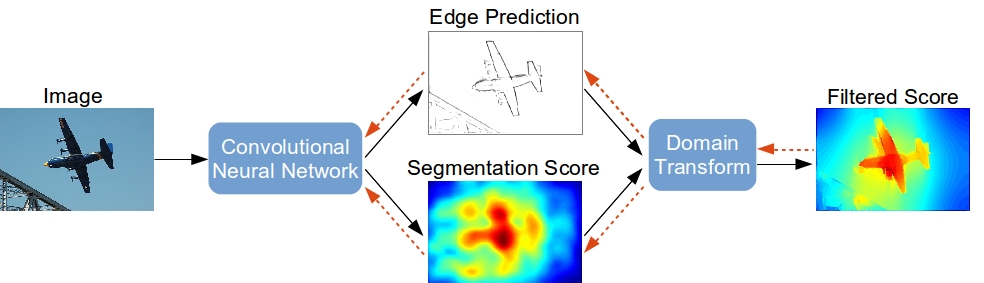 |
Semantic Image Segmentation with Task-Specific Edge Detection Using CNNs and a Discriminatively Trained Domain Transform
Liang-Chieh Chen, Jonathan T. Barron, George Papandreou, Kevin Murphy, Alan L. Yuille
In Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, Nevada, USA, June 2016.
[preprint (arxiv: 1511.03328)] [project] [code]
|
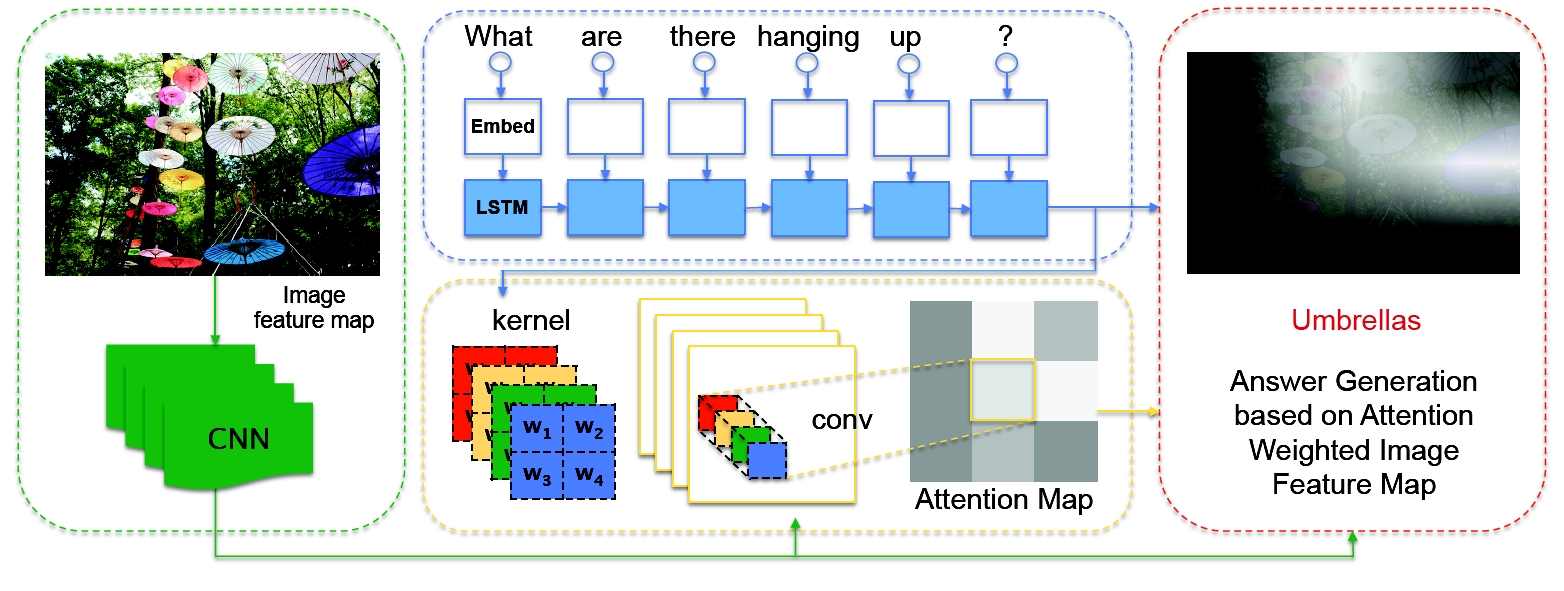 |
ABC-CNN: An Attention Based Convolutional Neural Network for Visual Question Answering
Kan Chen, Jiang Wang, Liang-Chieh Chen, Haoyuan Gao, Wei Xu, Ram Nevatia
Technical Report
[preprint (arxiv: 1511.05960)]
|
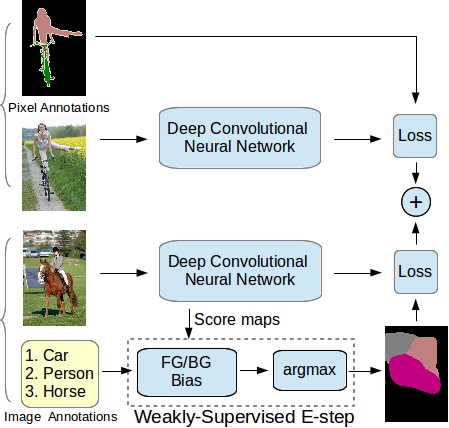 |
Weakly- and Semi-Supervised Learning of a Deep Convolutional Network for
Semantic Image Segmentation
George Papandreou*, Liang-Chieh Chen*, Kevin Murphy, Alan L. Yuille
(*equal contribution)
In International Conference on Computer Vision (ICCV), Santiago, Chile, December 2015.
[preprint (arxiv: 1502.02734)] [spotlight] [project] [code]
|
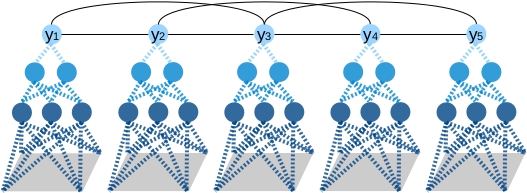 |
Learning Deep Structured Models (oral)
Liang-Chieh Chen*, Alexander G. Schwing*, Alan L. Yuille, Raquel Urtasun
(*equal contribution)
In International Conference on Machine Learning (ICML), Lille, France, July 2015.
[pdf] [talk]
|
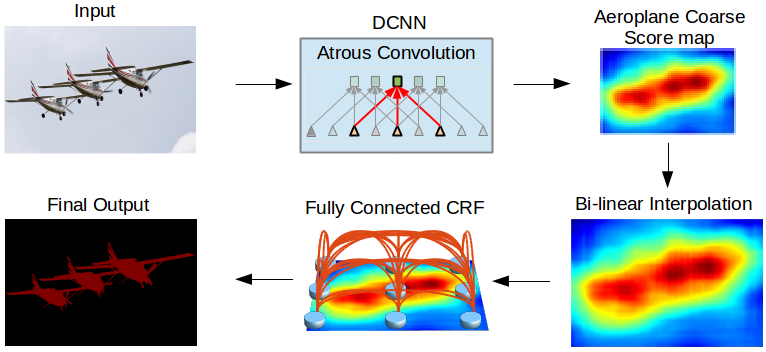 |
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
Liang-Chieh Chen*, George Papandreou*, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille
(*equal contribution)
In International Conference on Learning Representations (ICLR), San Diego, California, USA, May 2015.
[preprint (arXiv:1412.7062)] [project] [code]
|
 |
Beat the MTurkers: Automatic Image Labeling from Weak 3D Supervision
Liang-Chieh Chen, Sanja Fidler, Alan L. Yuille, Raquel Urtasun
In Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, Ohio, USA, June 2014.
[pdf] [Supplementary Doc] [project] [CAD models]
|
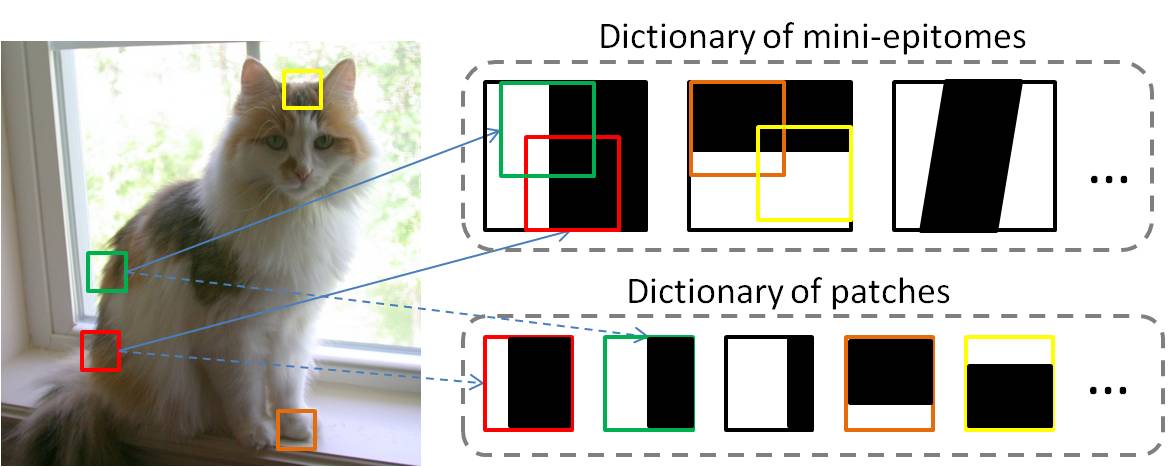 |
Modeling Image Patches with a Generic Dictionary of Mini-Epitomes
George Papandreou, Liang-Chieh Chen, Alan L. Yuille
In Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, Ohio, USA, June 2014.
[pdf] [Supplementary Doc]
|
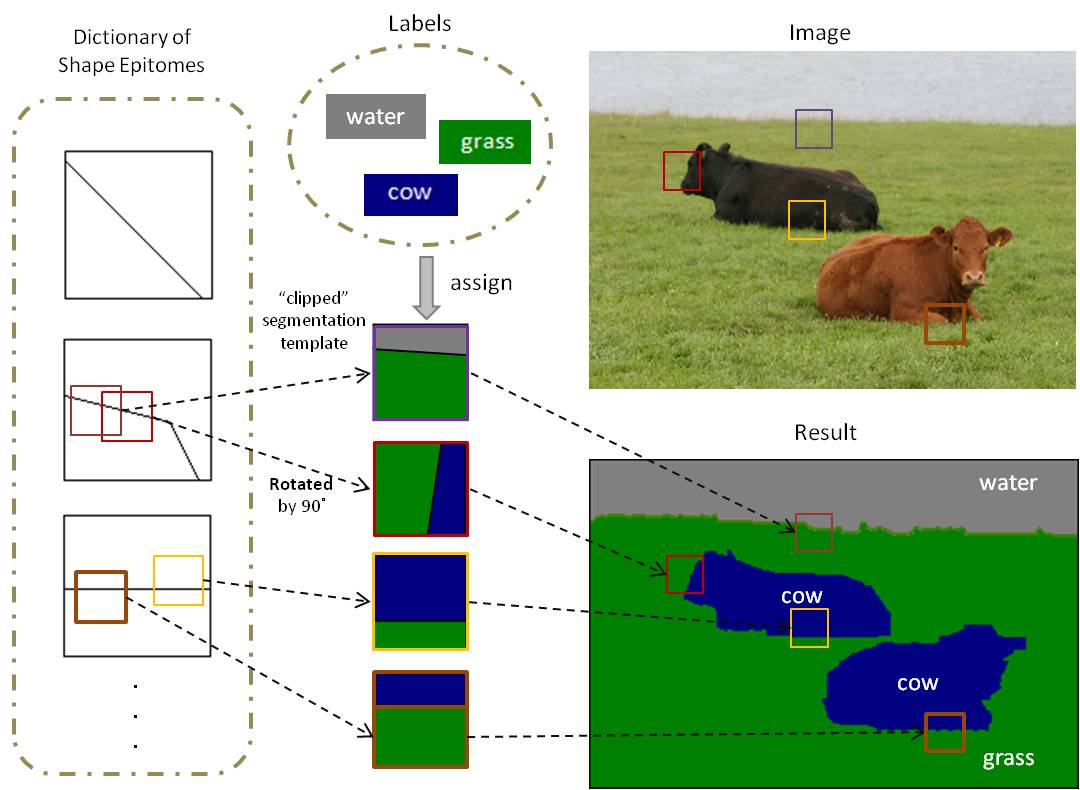 |
Learning a Dictionary of Shape Epitomes with Applications to Image Labeling
Liang-Chieh Chen, George Papandreou, Alan L. Yuille
In International Conference on Computer Vision (ICCV), Sydney, Australia, Dec. 2013.
[pdf] [Supplementary Doc]
|
|