Liang-Chieh (Jay) Chen- Home Page
 |
Liang-Chieh (Jay) Chen Email: lcchen at cs dot ucla dot edu |
About Me
I am currently a Research Scientist at Apple AI/ML, building cutting-edge visual generative models.
I am widely recognized for my contributions to the DeepLab series (co-developed with George Papandreou): DeepLabv1, DeepLabv2, DeepLabv3, DeepLabv3+. Since December 2014, our introduced atrous convolution (also known as convolution with holes or dilated convolution) has become a foundational technique for dense prediction tasks.
Influential DeepLab derivatives include Auto-DeepLab, Panoptic-DeepLab (winning method of the Mapillary Vistas Panoptic Segmentation track at ICCV 2019, and top performer on Cityscapes leaderboards), Axial-DeepLab, ViP-DeepLab, MaX-DeepLab, and kMaX-DeepLab.
I am also known for my collaborative work on MobileNetv2 and MobileNetv3, which have become standards for efficient neural network design on mobile devices.
Previously, I was a Senior Principal Scientist at Amazon in 2025, and a Research Scientist and Manager at ByteDance Research/TikTok from 2023 to 2025. Prior to that, I spent seven years as a Research Scientist at Google Research in Los Angeles (2016–2023). I received my Ph.D. in Computer Science from the University of California, Los Angeles, in 2015, advised by Alan L. Yuille. I received my M.S. in Electrical and Computer Engineering from the University of Michigan, Ann Arbor.
News
 |
|
DeltaTok has been accepted as CVPR 2026 highlight. This innovative tokenizer compresses VFM frame features into a single, compact token, powering DeltaWorld—a generative world model capable of simulating diverse and plausible future scenarios.
Interested in computer vision, visual generation, or representation learning? We are looking for motivated Ph.D. students and full-time researchers to join our team. Feel free to contact me to discuss open positions.
Activities
Area Chair for ICCV 2019, CVPR 2020/2023/2024, ECCV 2020/2024, NeurIPS 2022/2024/2025, ICML 2025/2026.
Senior/Lead Area Chair: ICCV 2025, CVPR 2025/2026, ECCV 2026, NeurIPS 2026.
Action Editor for TMLR 2025/2026.
Reviewer for CVPR, ECCV, ICCV, NeurIPS.
Selected Recent Publications
 |
Taming Outlier Tokens in Diffusion Transformers |
 |
Large Language Models are Universal Reasoners for Visual Generation |
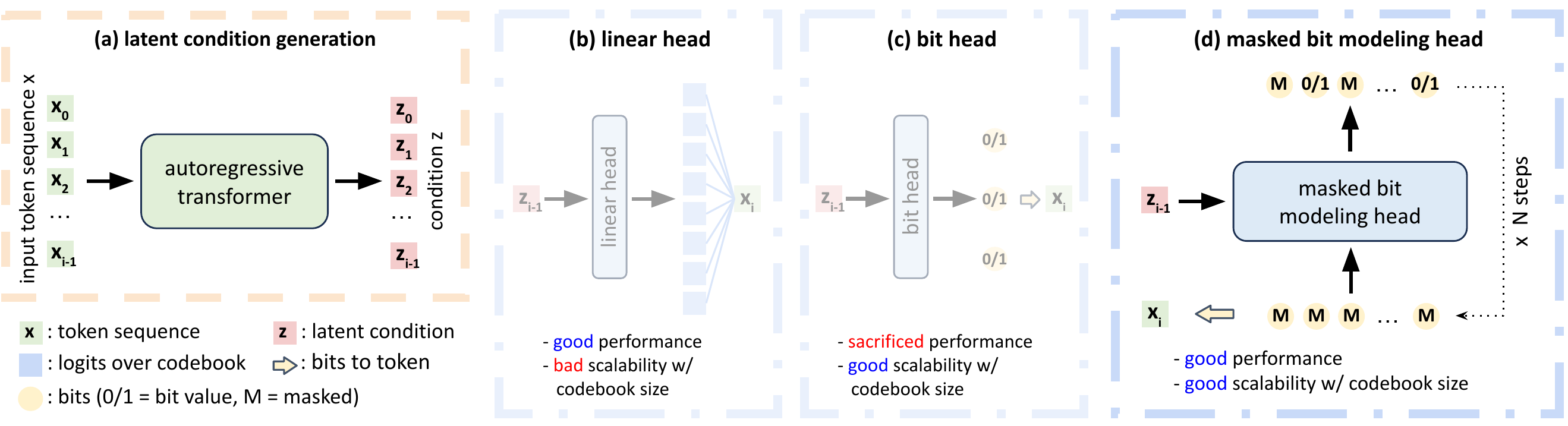 |
Autoregressive Image Generation with Masked Bit Modeling |
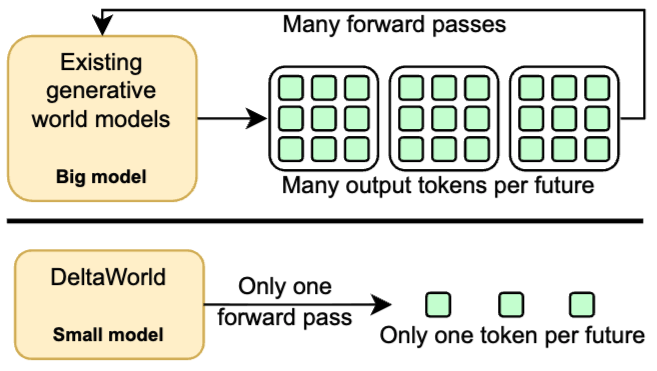 |
A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens (highlight) |
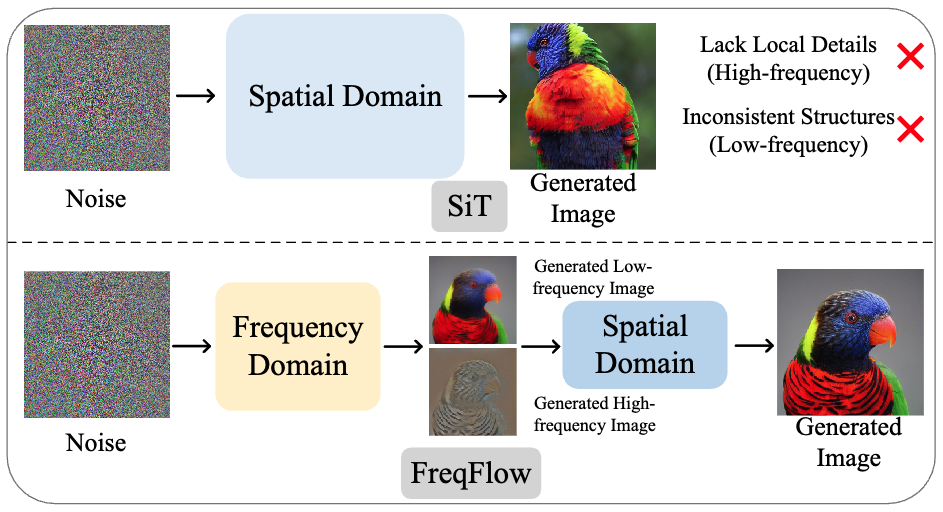 |
Frequency-Aware Flow Matching for High-Quality Image Generation |