Liang-Chieh (Jay) Chen- Home Page
 |
Liang-Chieh Chen Email: lcchen at cs dot ucla dot edu |
About me
I am currently a Research Scientist at ByteDance / TikTok. My research interests include Computer Vision, and Deep Learning.
Before joining ByteDance, I was a Research Scientist at Google, Los Angeles. I received my Ph.D. in Computer Science at UCLA under the supervision of Alan L. Yuille.
News
For motivated Ph.D. students looking for internships or full-time positions, feel free to contact me for details. Our team works on fundamental research on visual recognition, representation learning, and deep learning.
Check out DiMR, a multi-resolution network for diffusion models.
Check out TiTok, a compact and mighty image tokenization.
Check out Video-3DGS, which enhances temporal consistency of video editors via 3D Gaussian Splatting.
COCONut, Crafting the Future of Segmentation Datasets with Exquisite Annotations in the Era of Big Data, is publicly available!
ViTamin, a Novel Scalable Vision Backbone in the Vision-Language Era, is open-source in PyTorch!
Papers
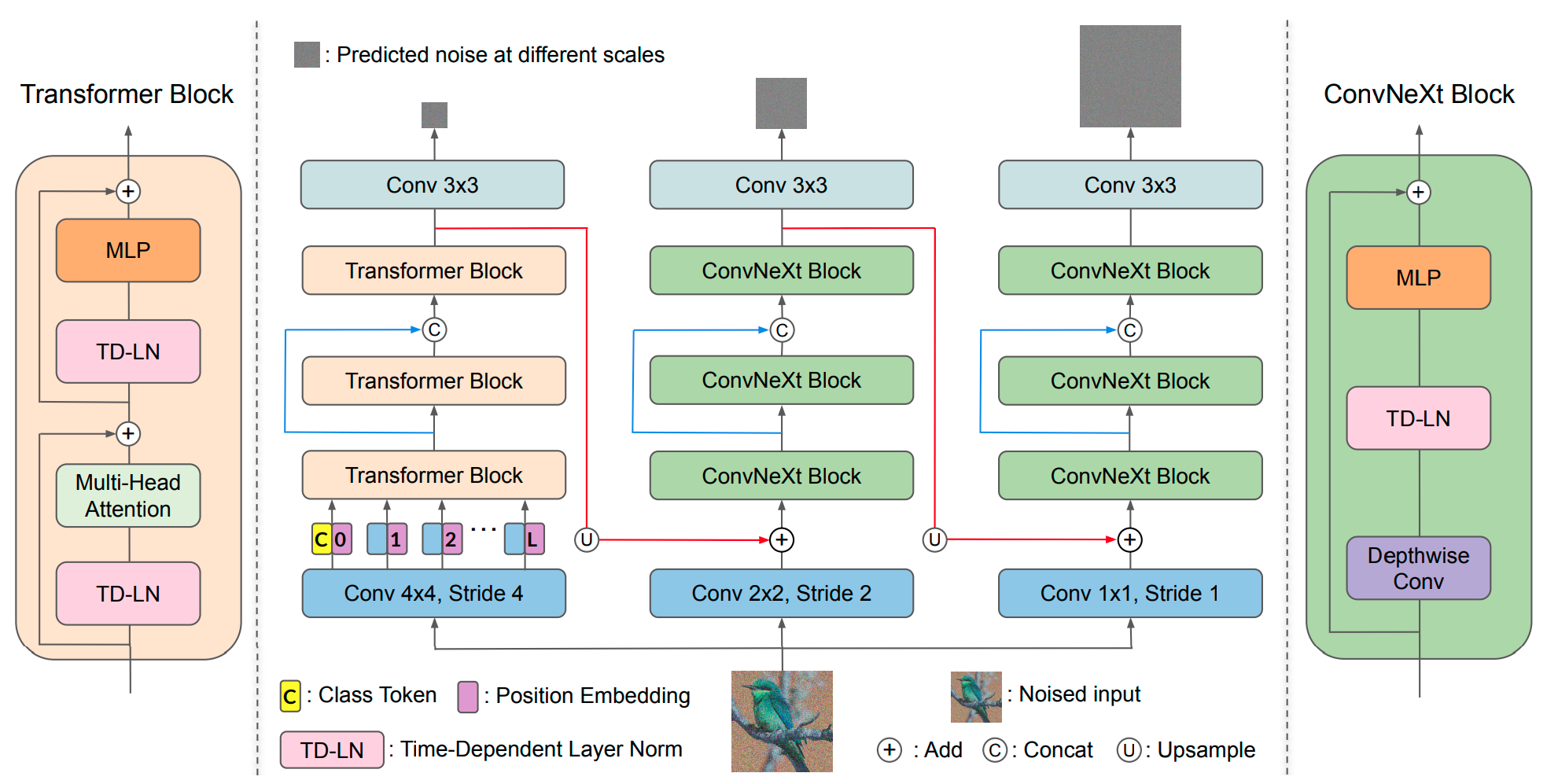 |
Alleviating Distortion in Image Generation via Multi-Resolution Diffusion Models |
 |
An Image is Worth 32 Tokens for Reconstruction and Generation |
 |
Enhancing Temporal Consistency in Video Editing by Reconstructing Videos with 3D Gaussian Splatting |
 |
COCONut: Modernizing COCO Segmentation |
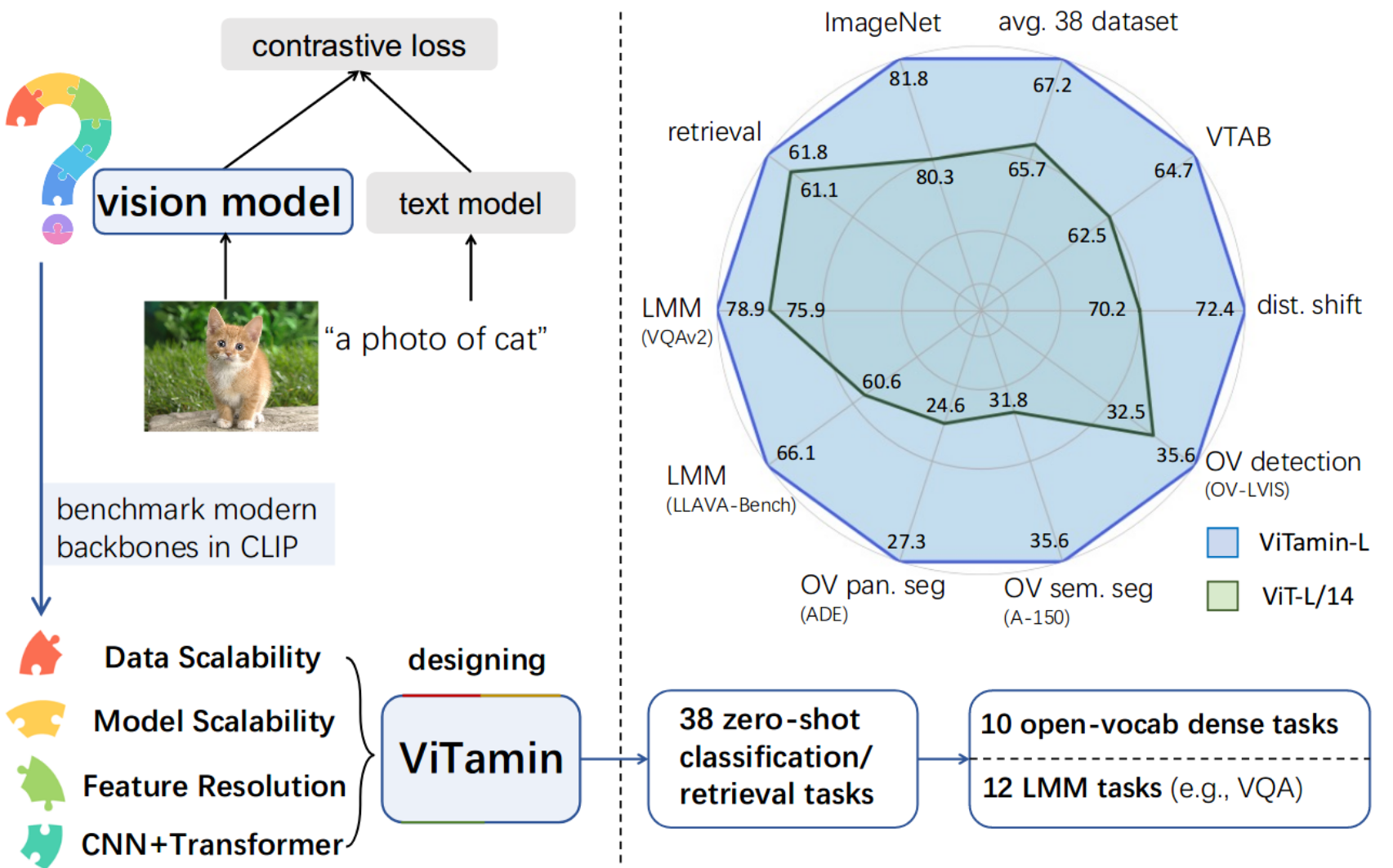 |
ViTamin: Designing Scalable Vision Models in the Vision-Language Era |
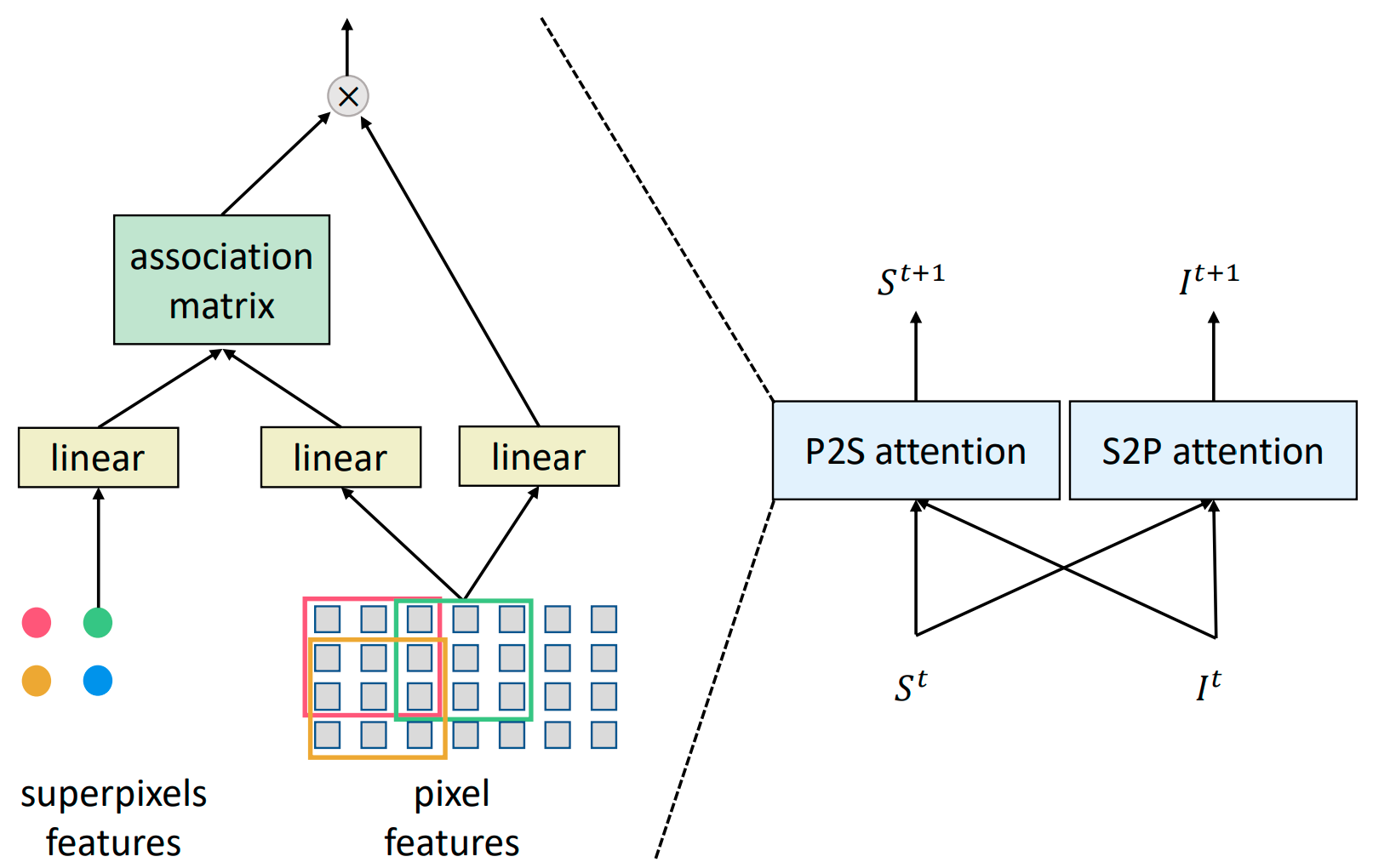 |
SPFormer: Enhancing Vision Transformer with Superpixel Representation |
 |
MaXTron: Mask Transformer with Trajectory Attention for Video Panoptic Segmentation |
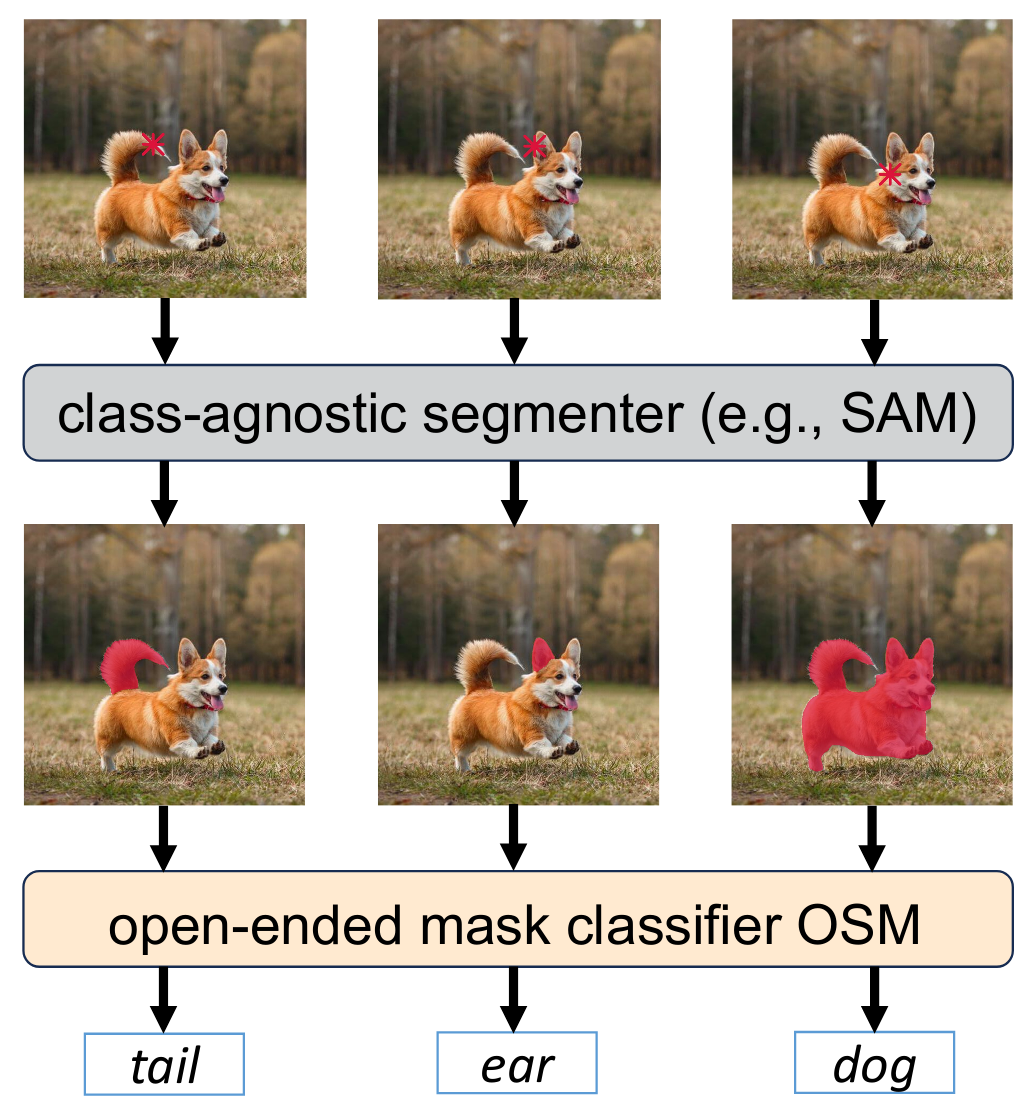 |
Towards Open-Ended Visual Recognition with Large Language Model |
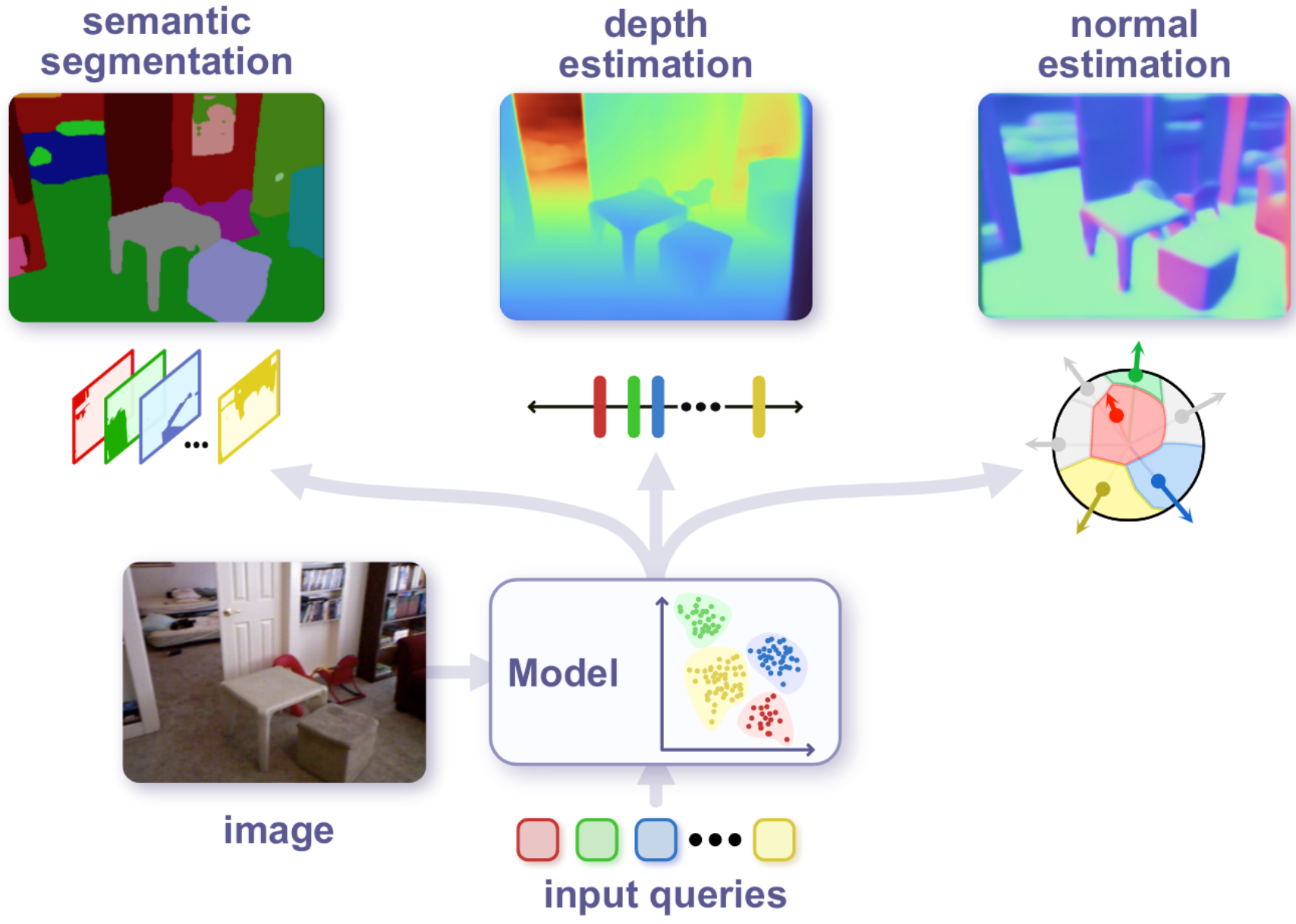 |
PolyMaX: General Dense Prediction with Mask Transformer |
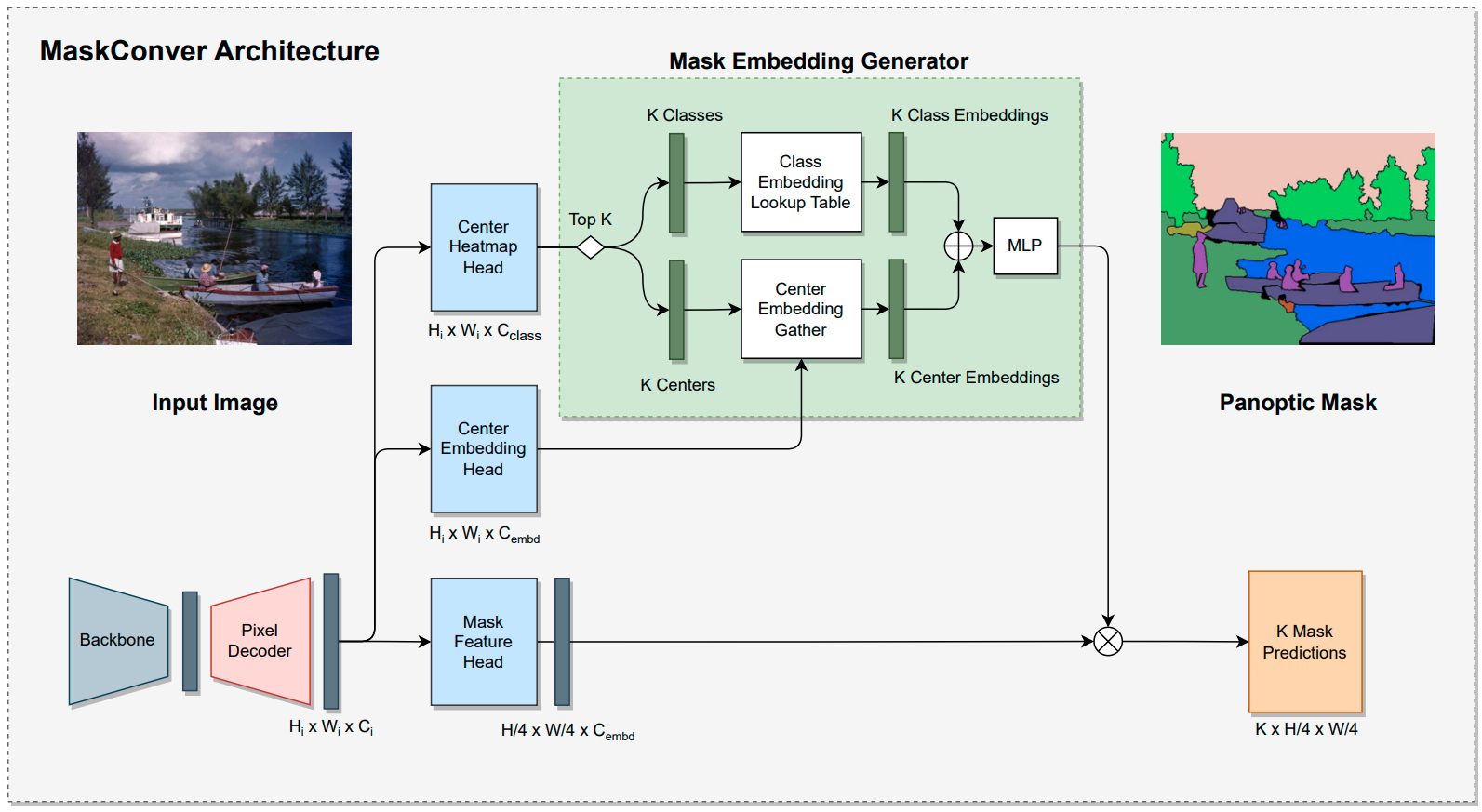 |
MaskConver: Revisiting Pure Convolution Model for Panoptic Segmentation |
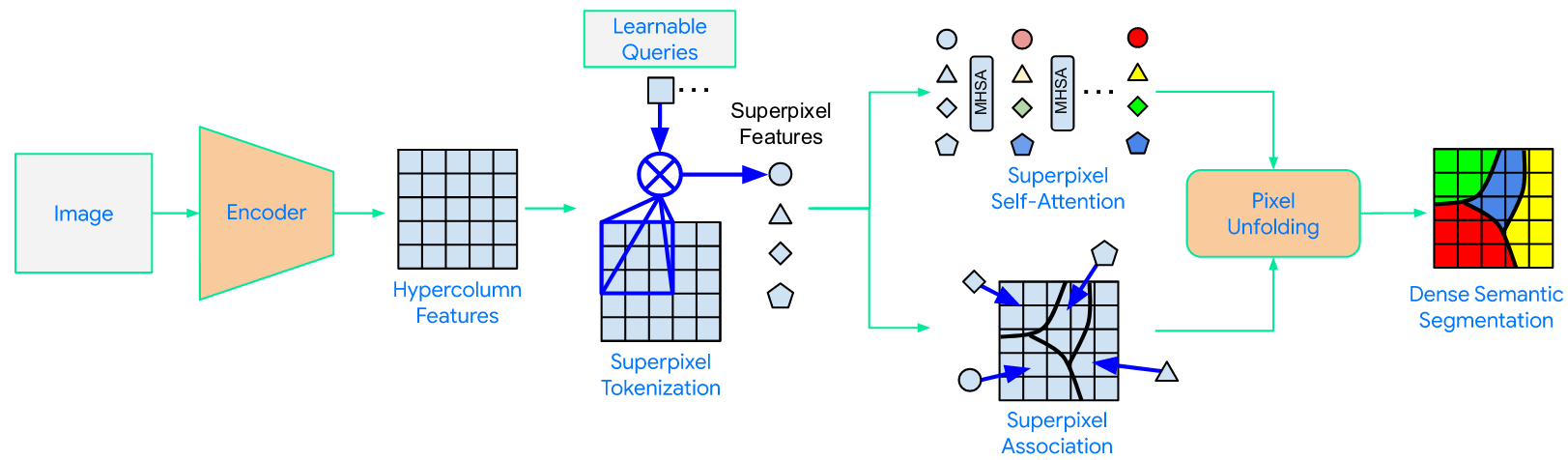 |
Superpixel Transformers for Efficient Semantic Segmentation |
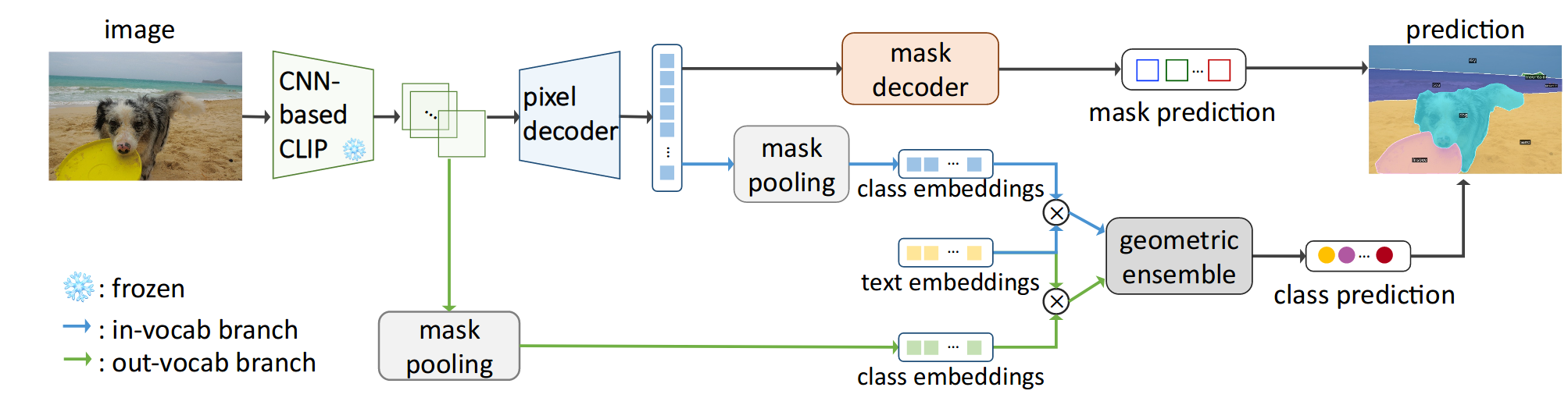 |
Convolutions Die Hard: Open-Vocabulary Segmentation with Single Frozen Convolutional CLIP |
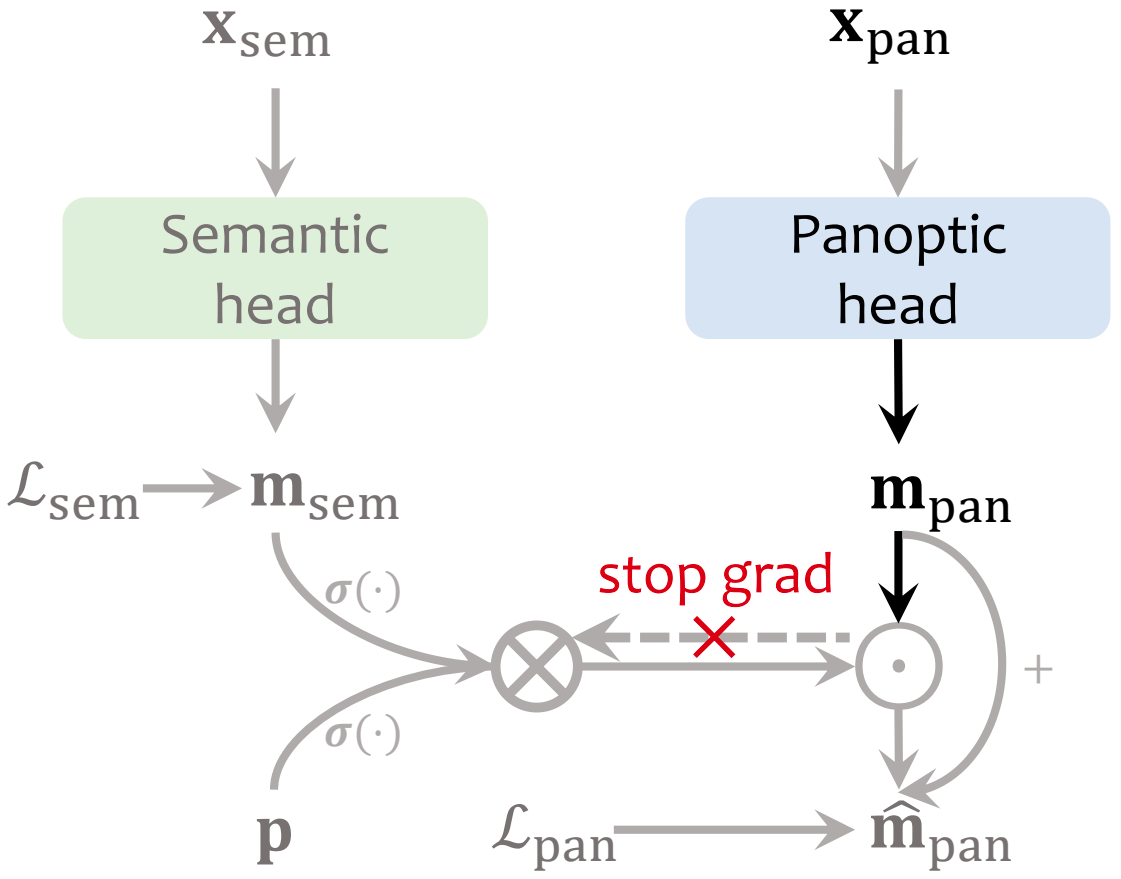 |
ReMaX: Relaxing for Better Training on Efficient Panoptic Segmentation |
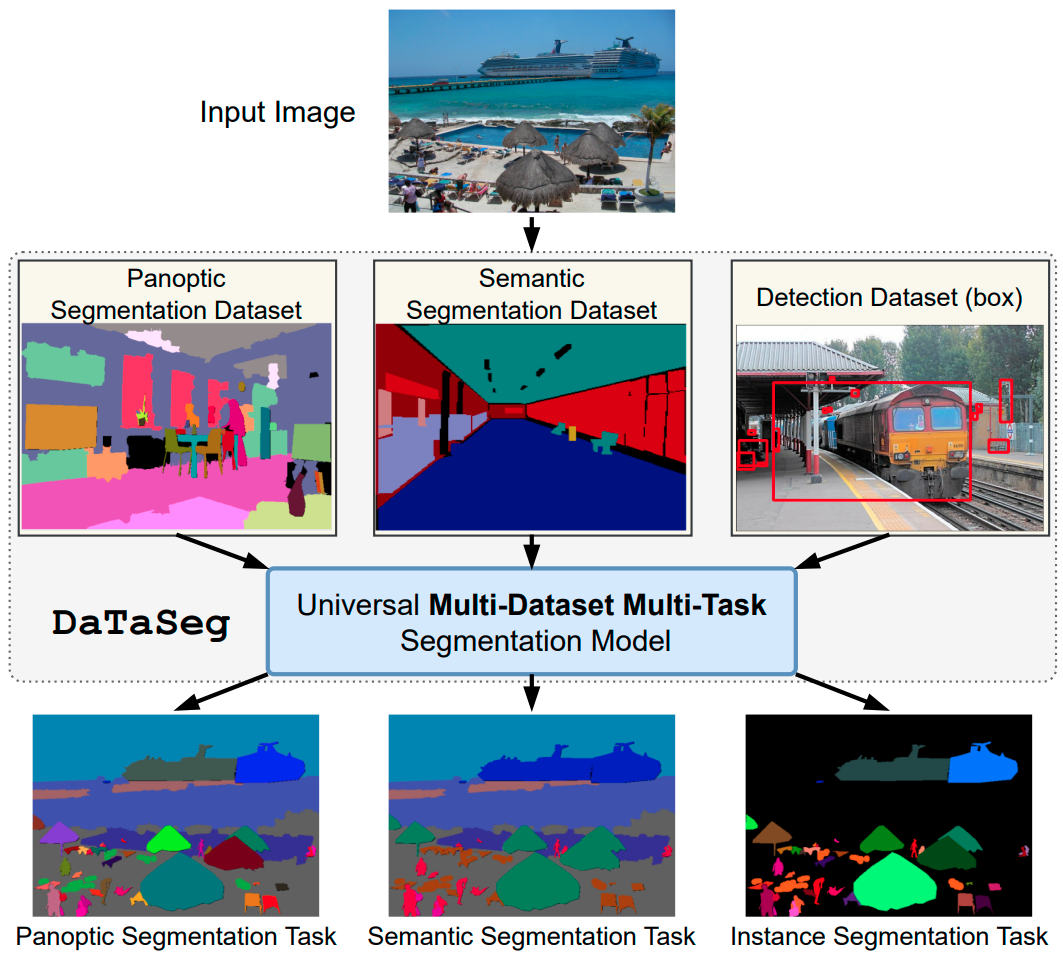 |
DaTaSeg: Taming a Universal Multi-Dataset Multi-Task Segmentation Model |
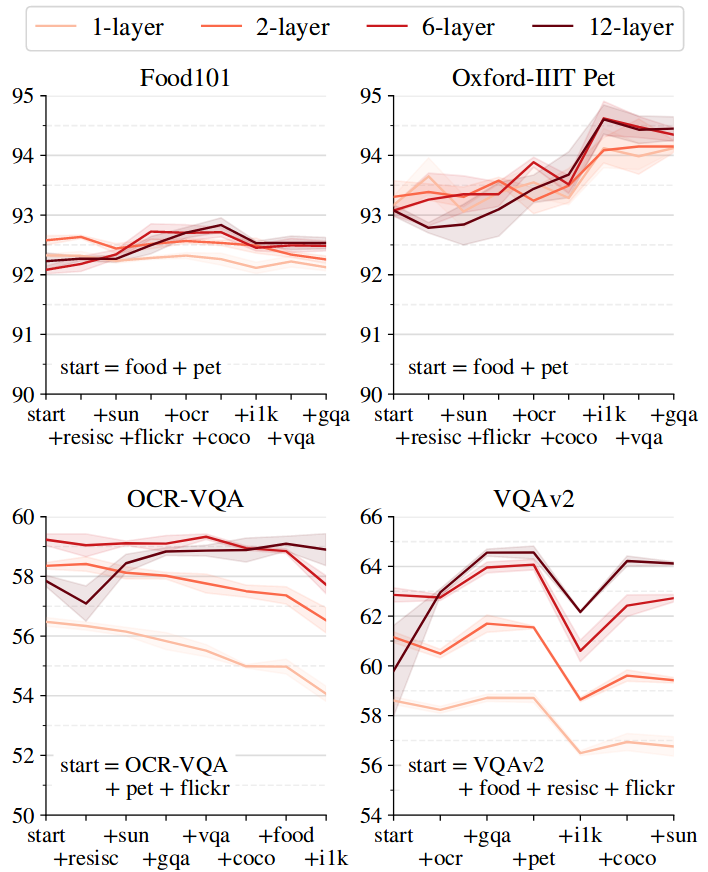 |
A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision |
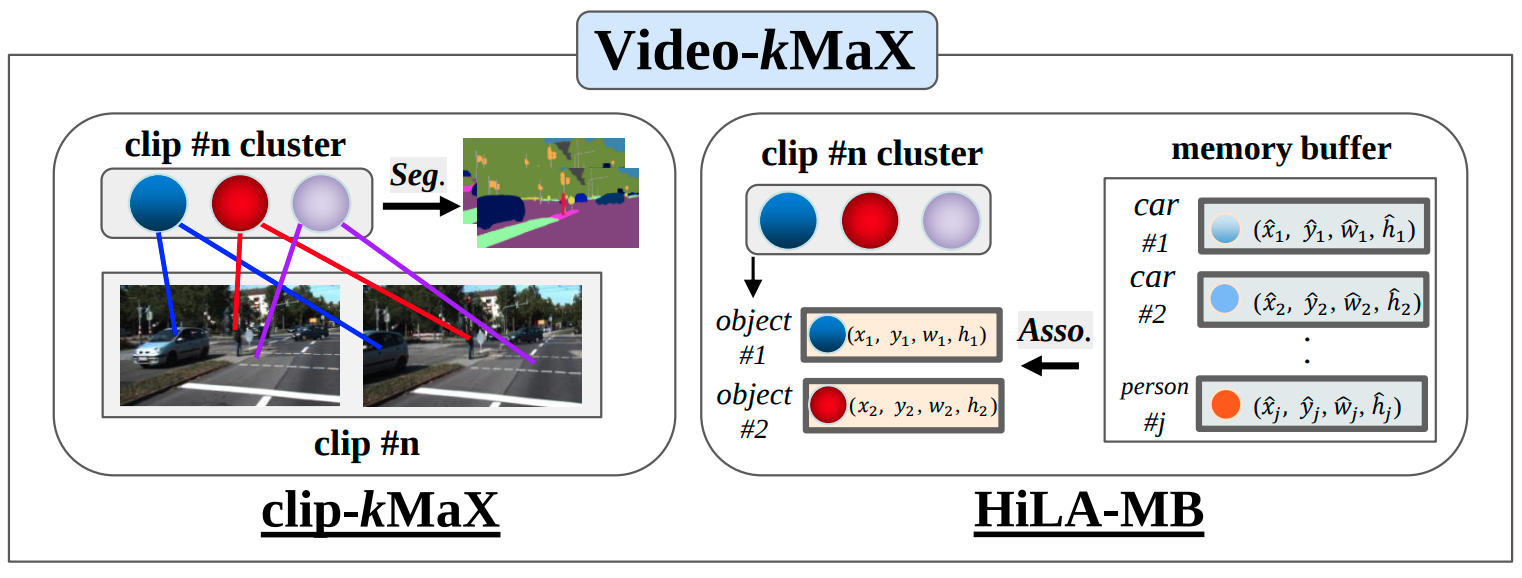 |
Video-kMaX: A Simple Unified Approach for Online and Near-Online Video Panoptic Segmentation |
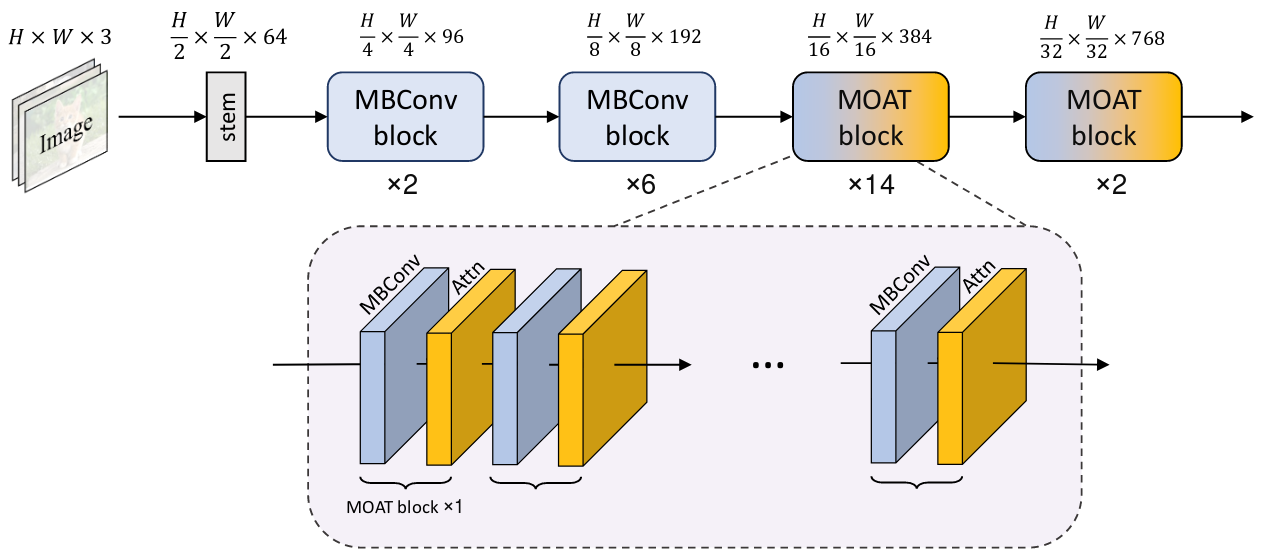 |
MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models |
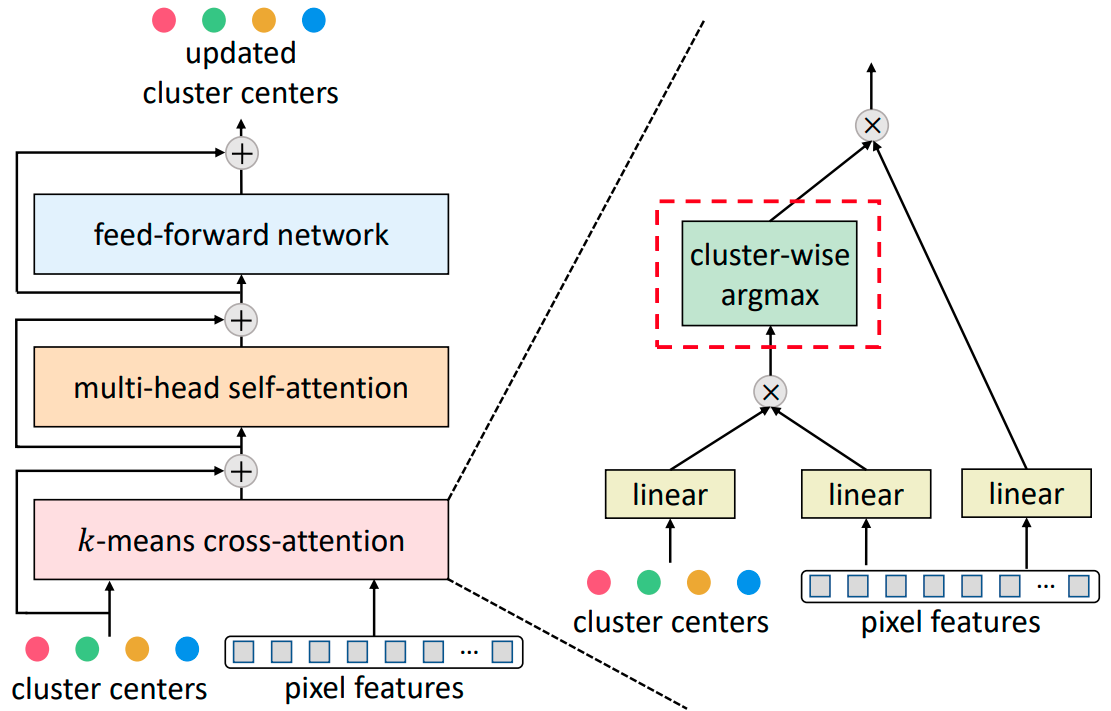 |
k-means Mask Transformer |
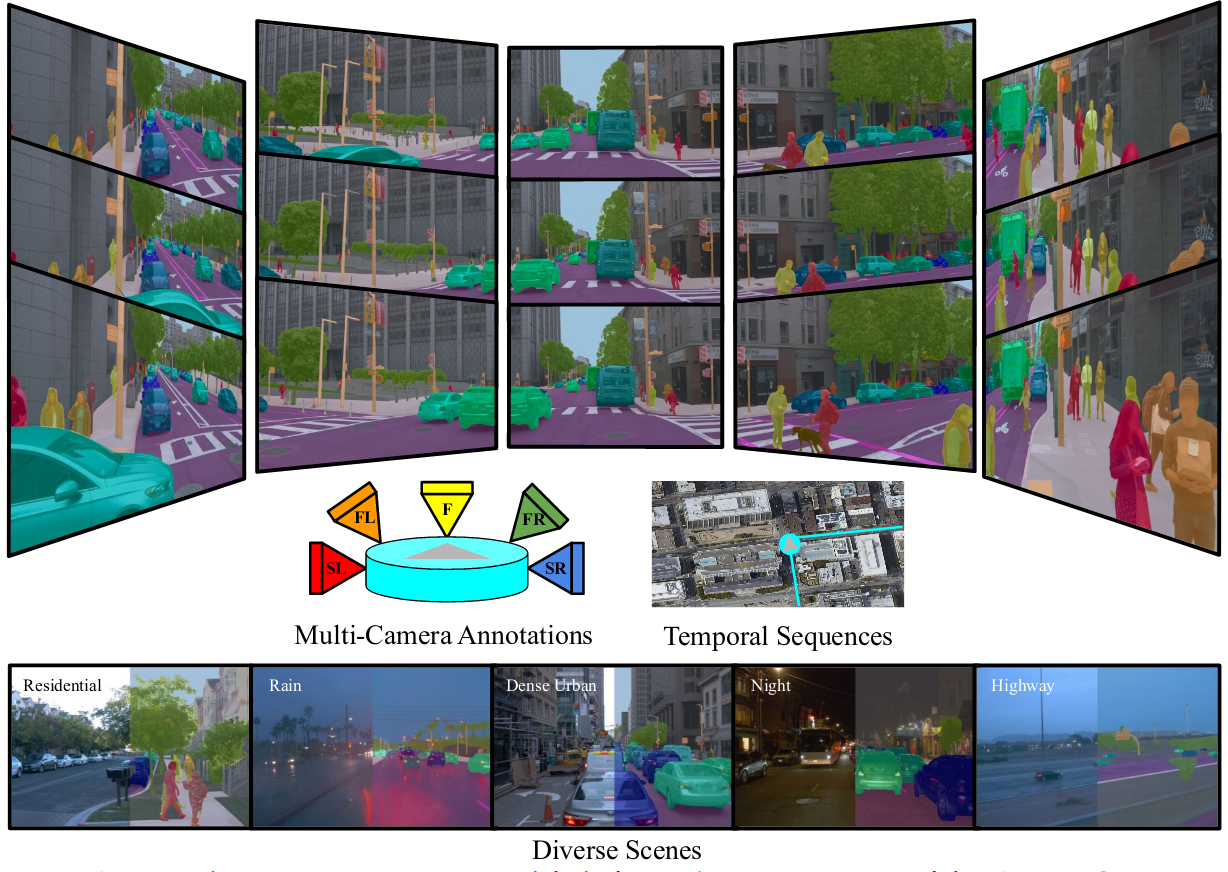 |
Waymo Open Dataset: Panoramic Video Panoptic Segmentation |
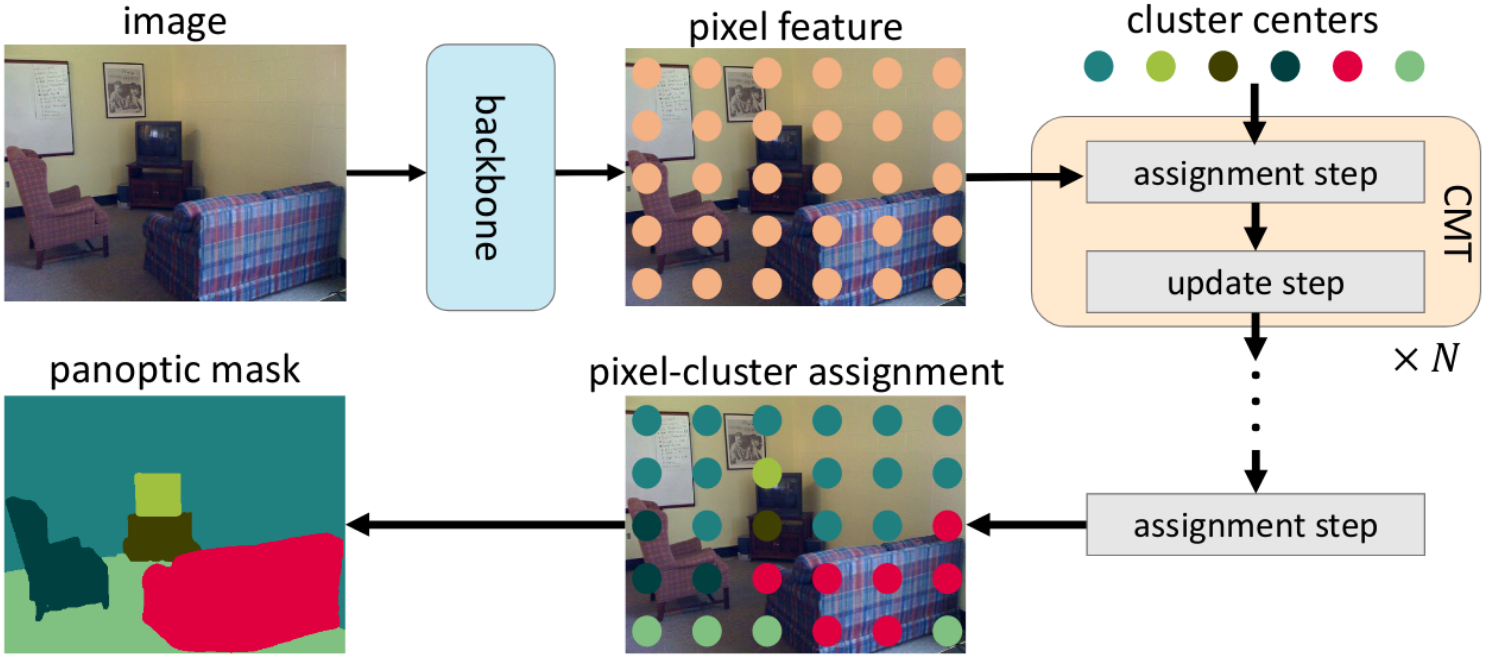 |
CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation (oral) |
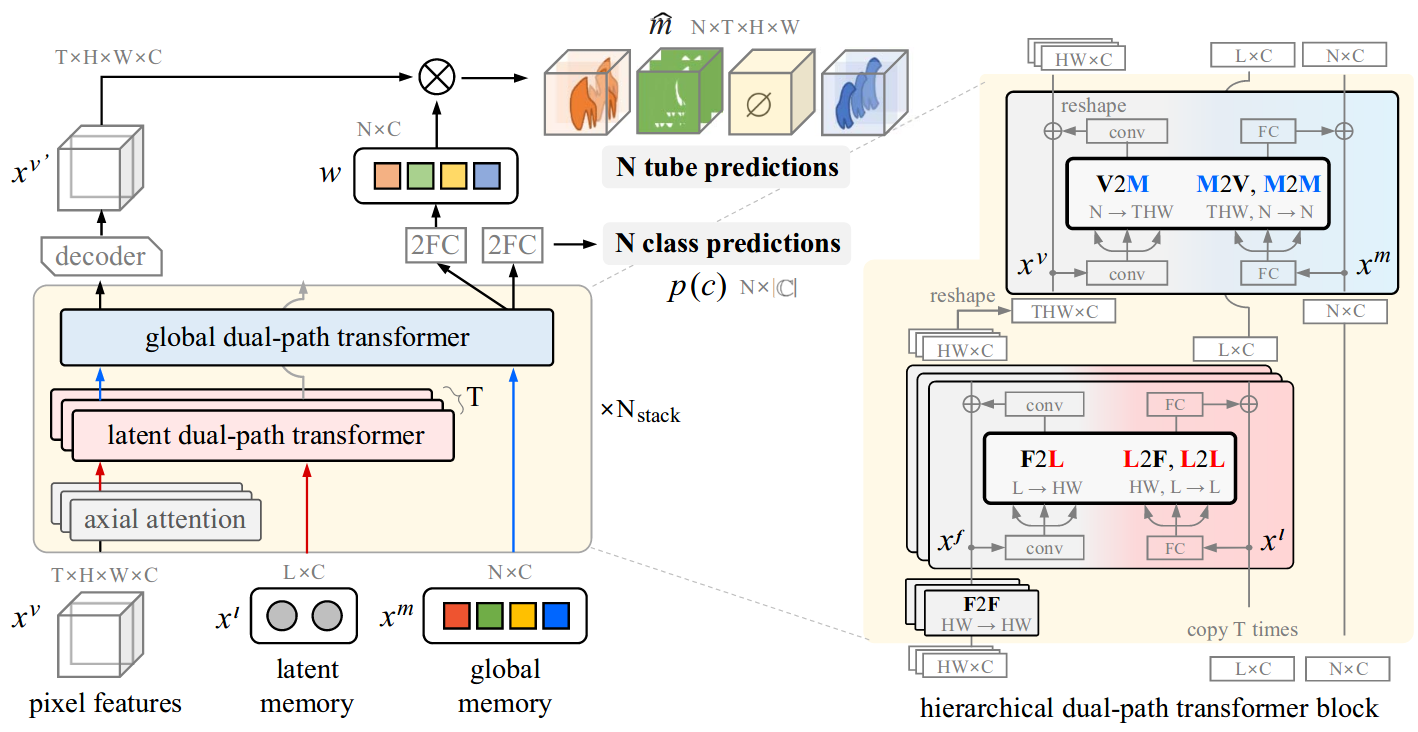 |
TubeFormer-DeepLab: Video Mask Transformer |
 |
DeepLab2: A TensorFlow Library for Deep Labeling |
 |
STEP: Segmenting and Tracking Every Pixel |
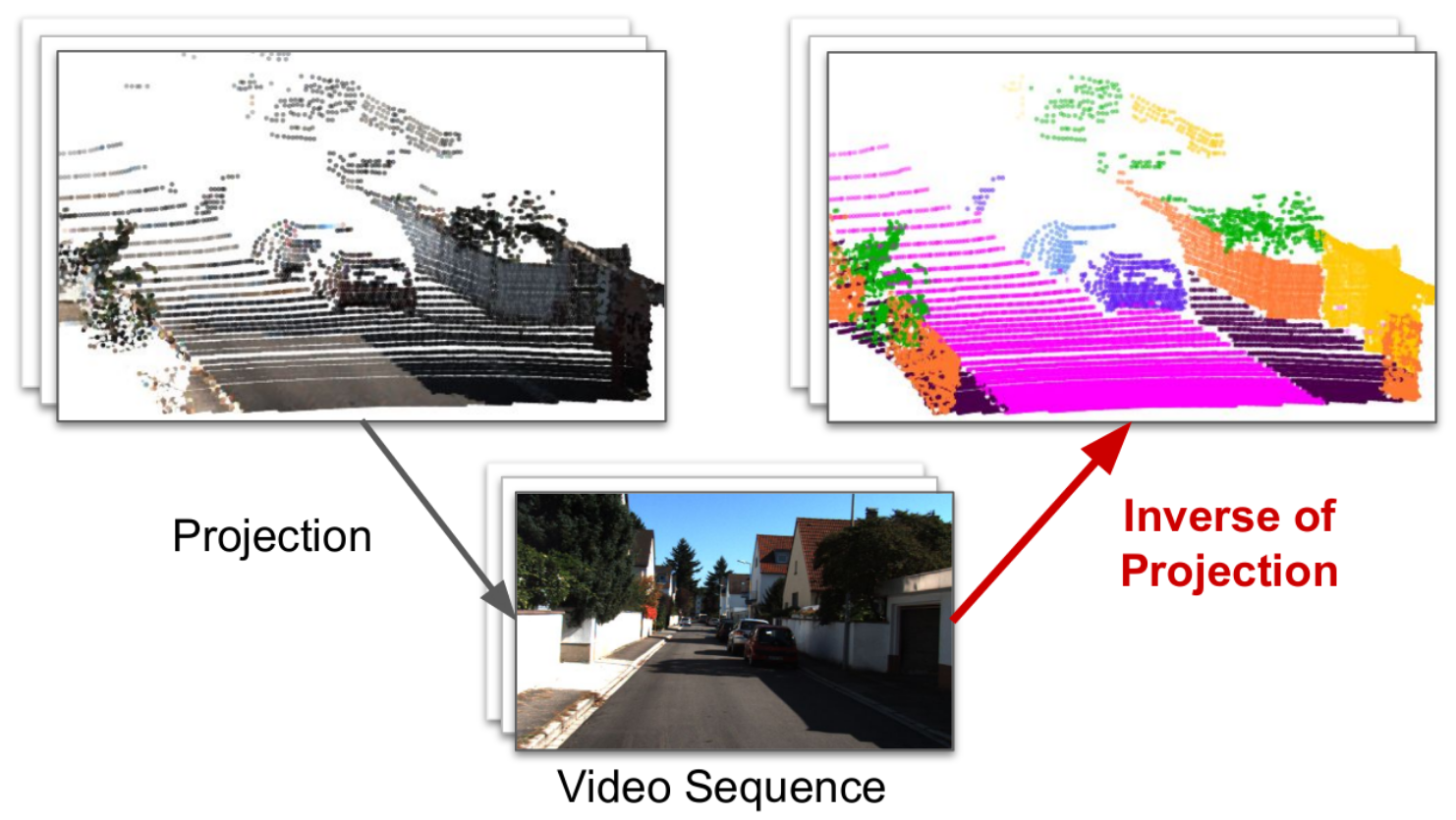 |
ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation |
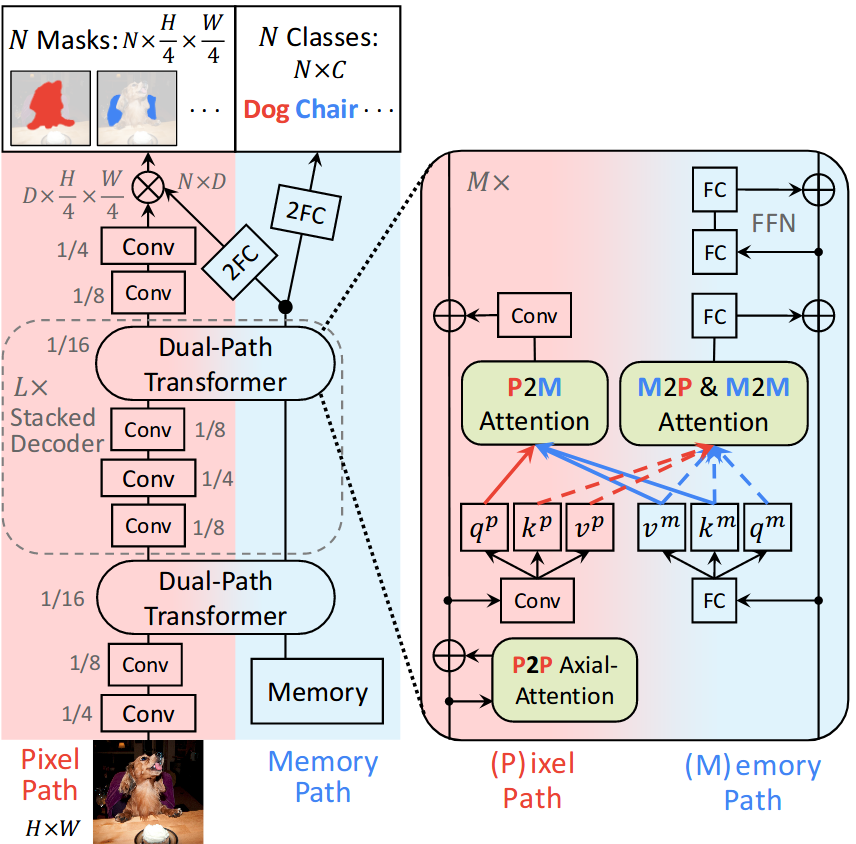 |
MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers |
 |
Scaling Wide Residual Networks for Panoptic Segmentation |
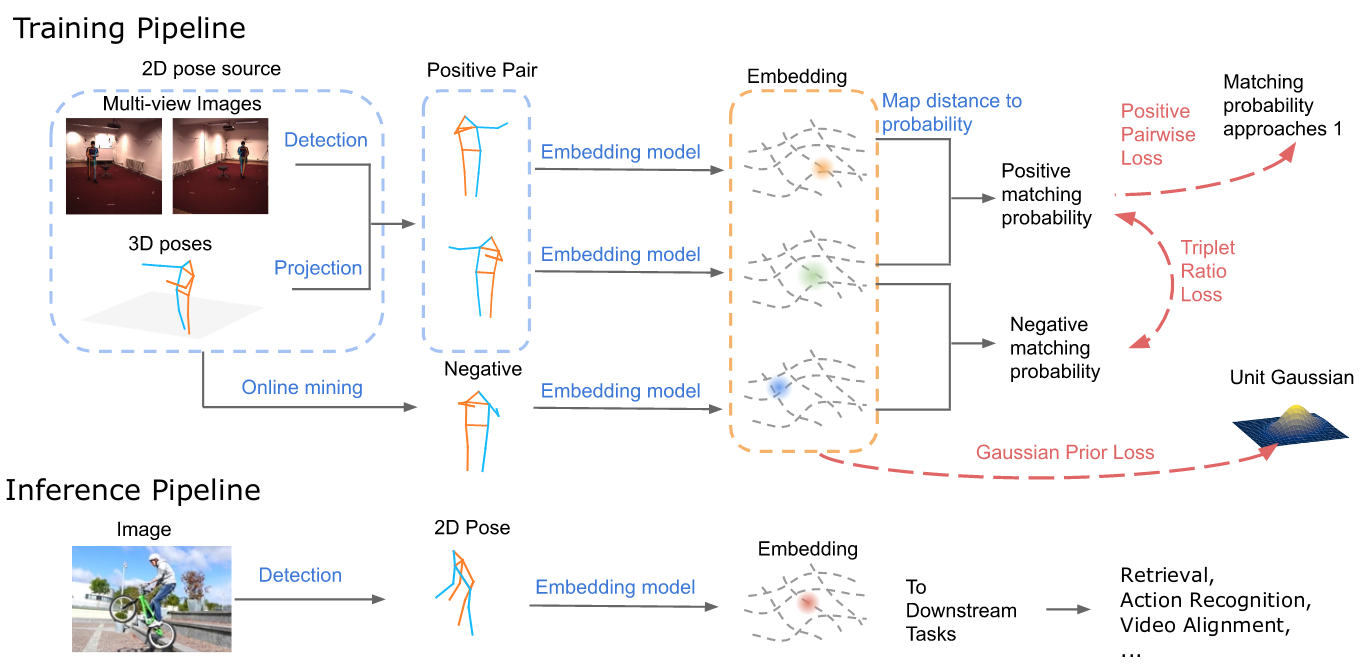 |
View-Invariant, Occlusion-Robust Probabilistic Embedding for Human Pose |
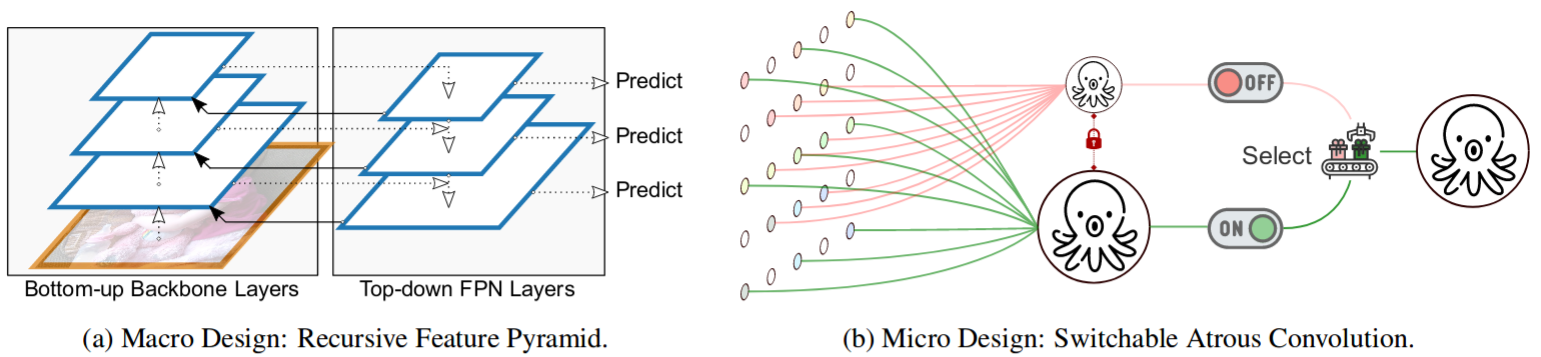 |
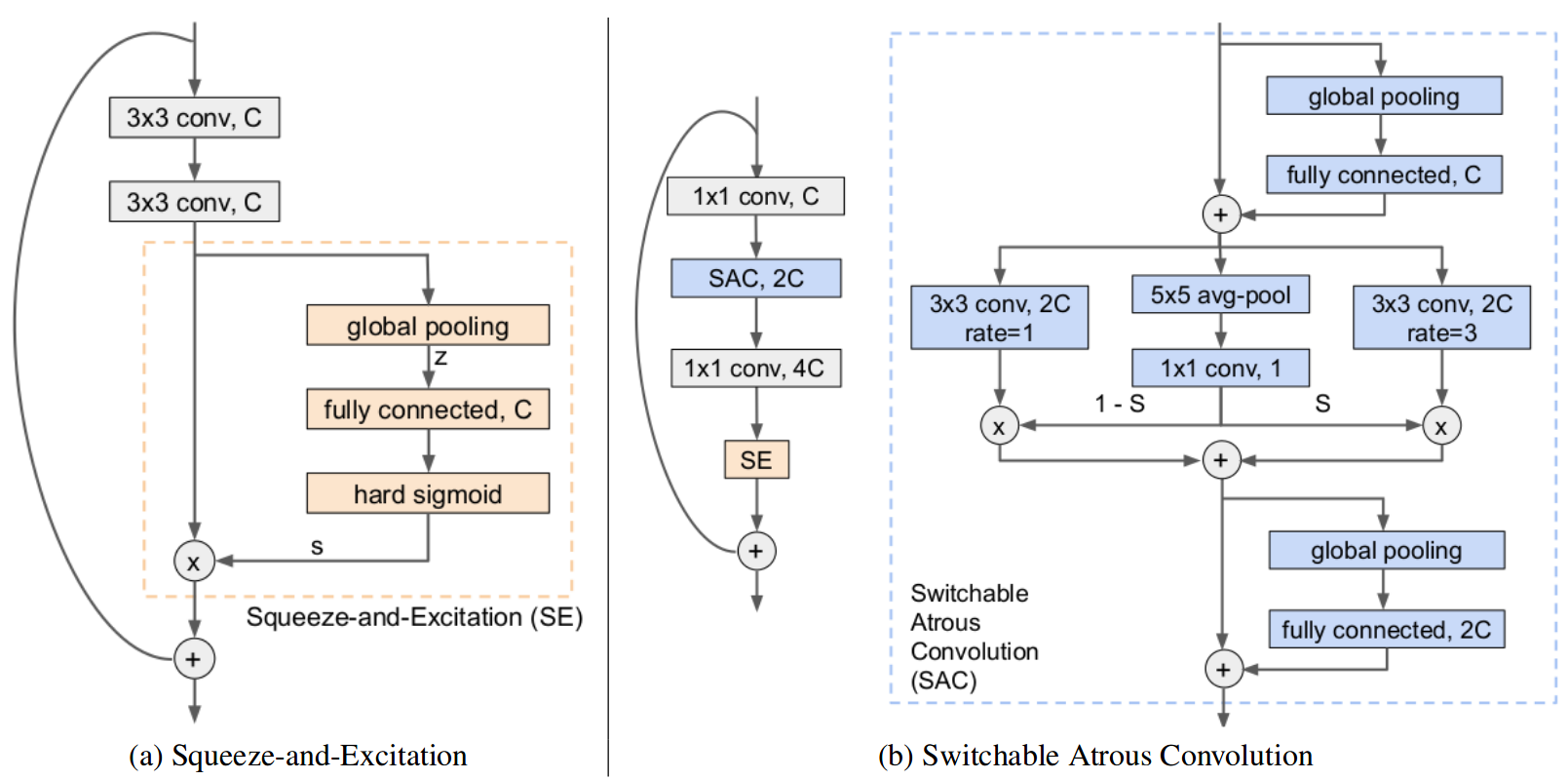
DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution |
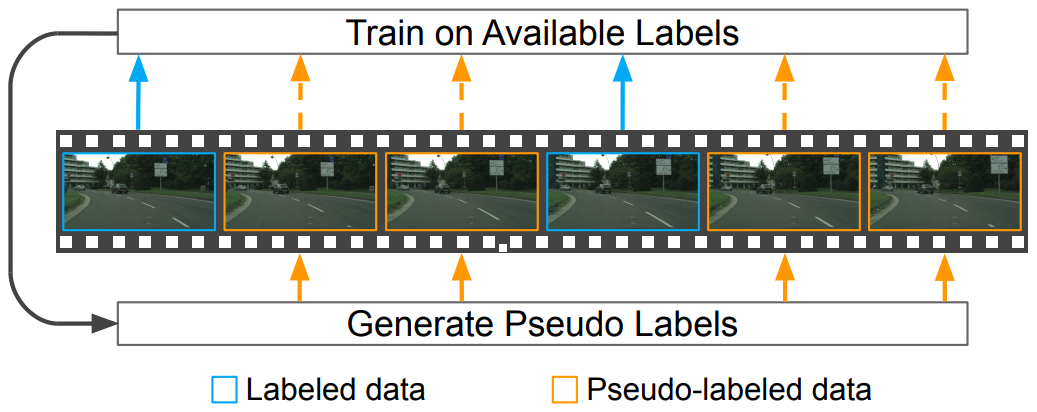 |
Naive-Student: Leveraging Semi-Supervised Learning in Video Sequences for Urban Scene Segmentation |
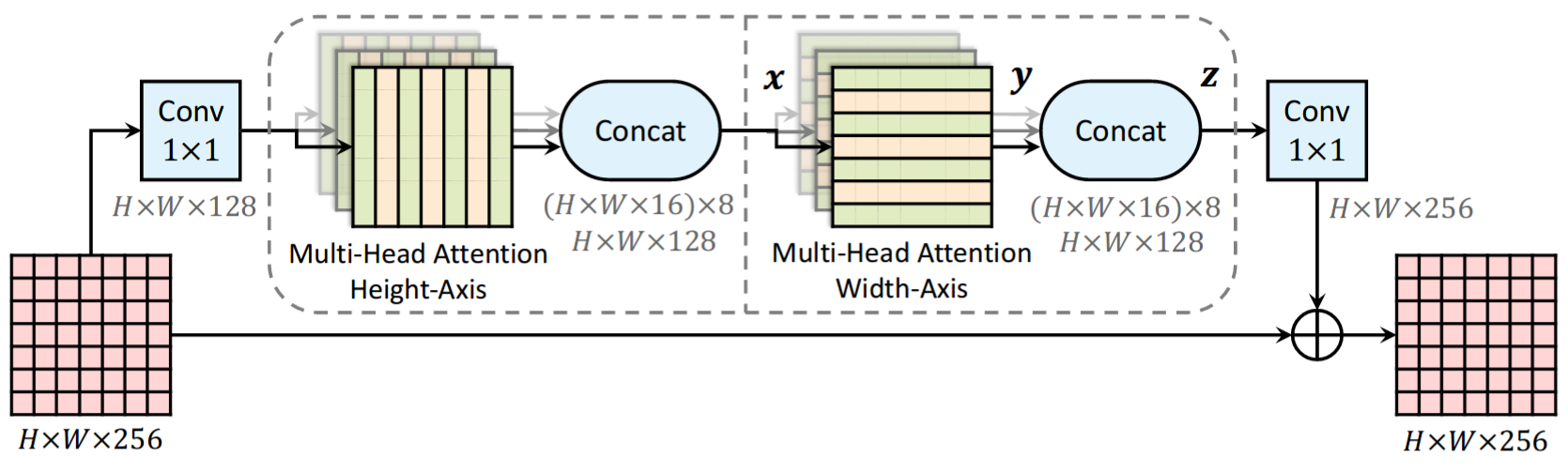 |
Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation (spotlight) |
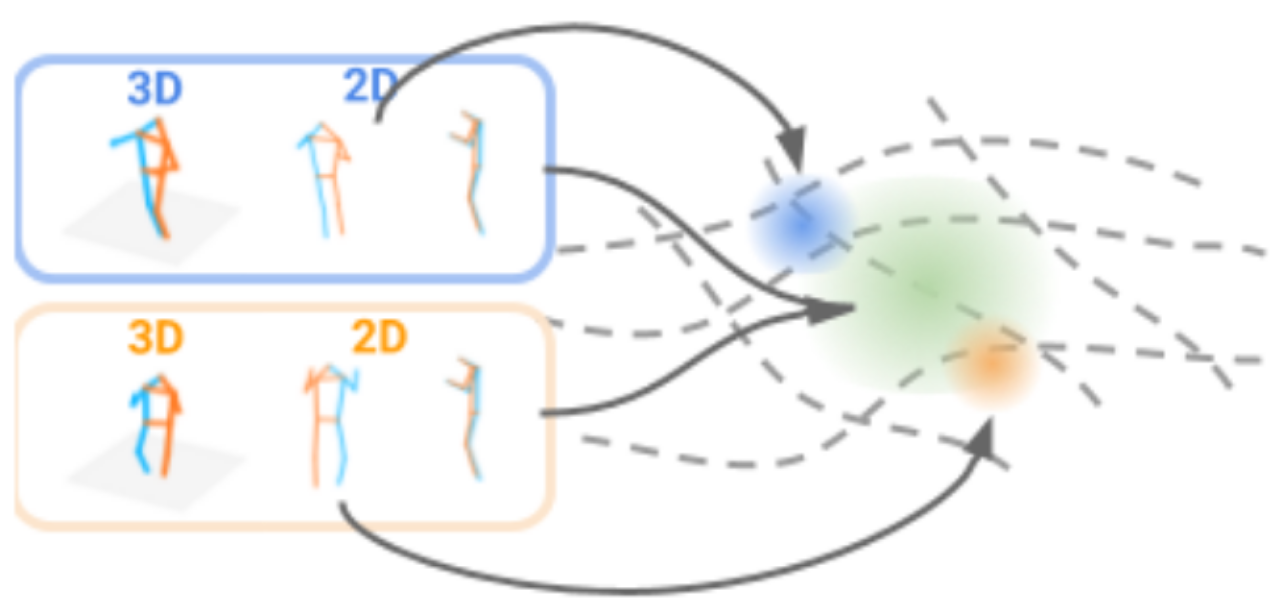 |
View-Invariant Probabilistic Embedding for Human Pose (spotlight) |
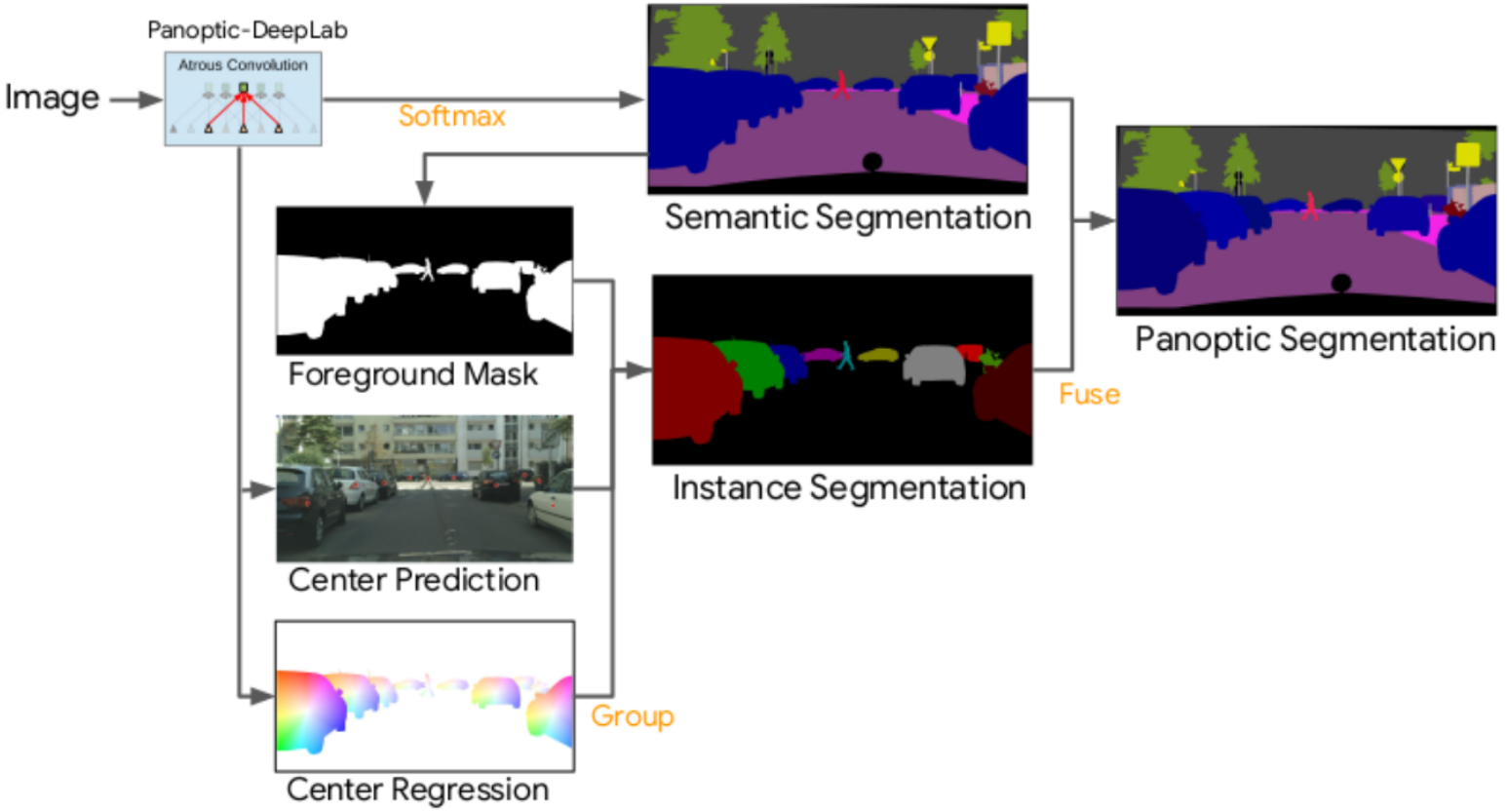 |
Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation |
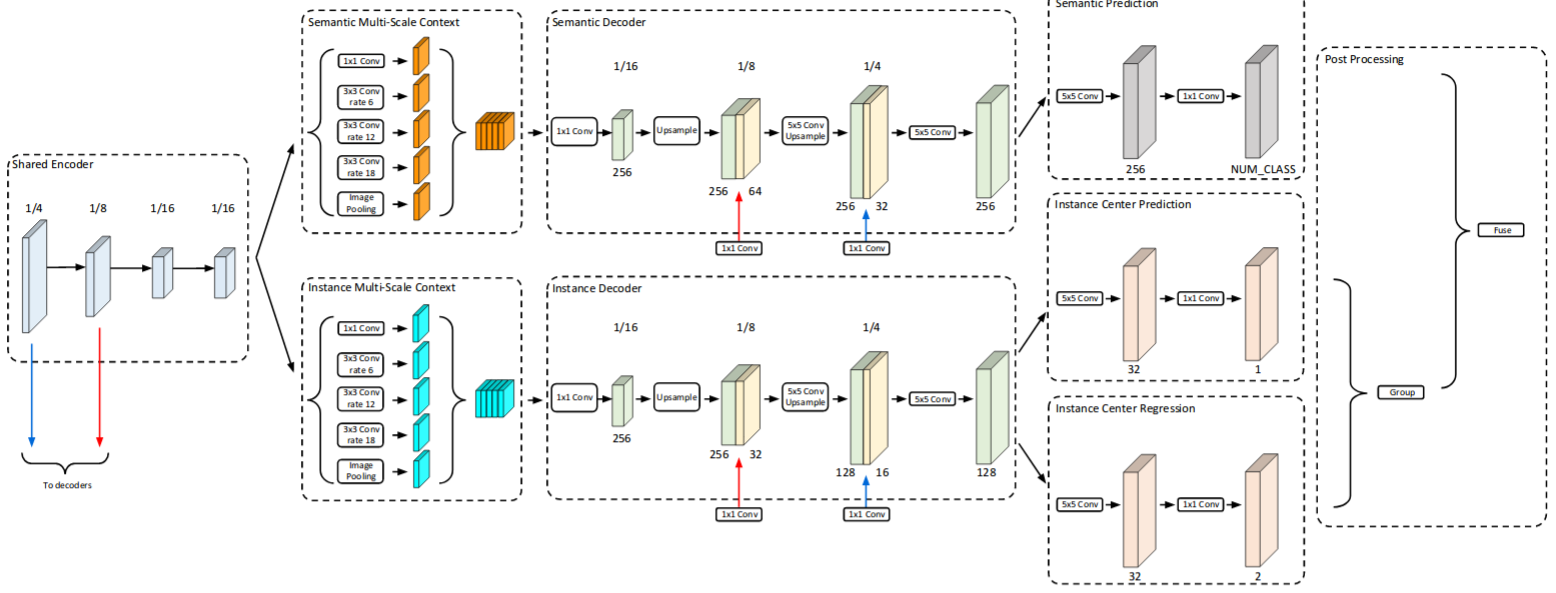 |
Panoptic-DeepLab |
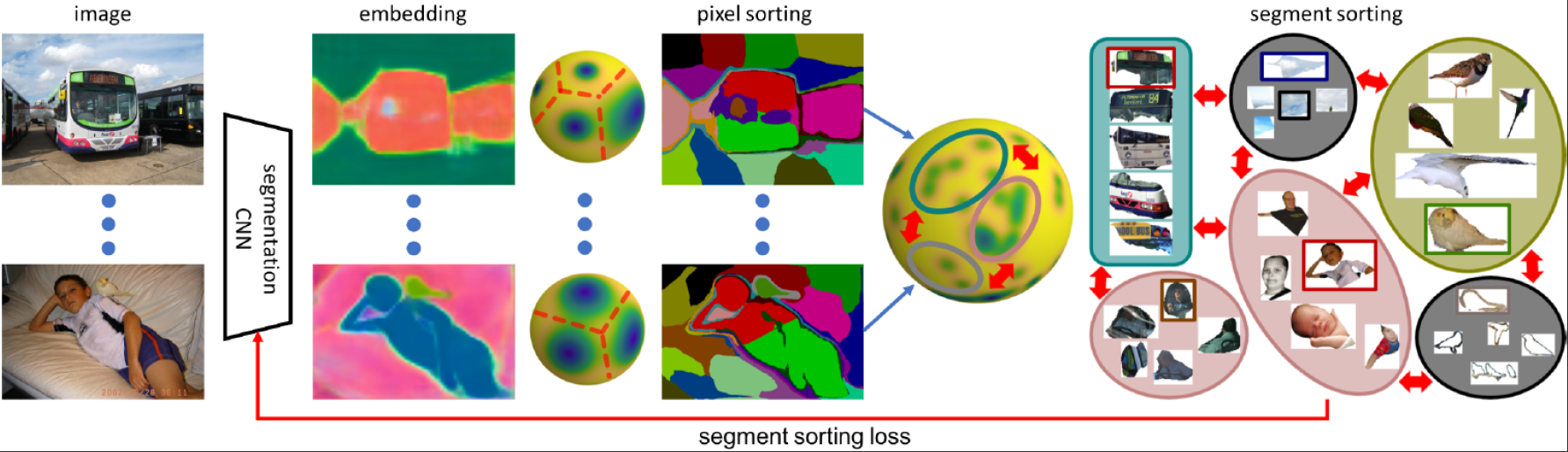 |
SegSort: Segmentation by Discriminative Sorting of Segments |
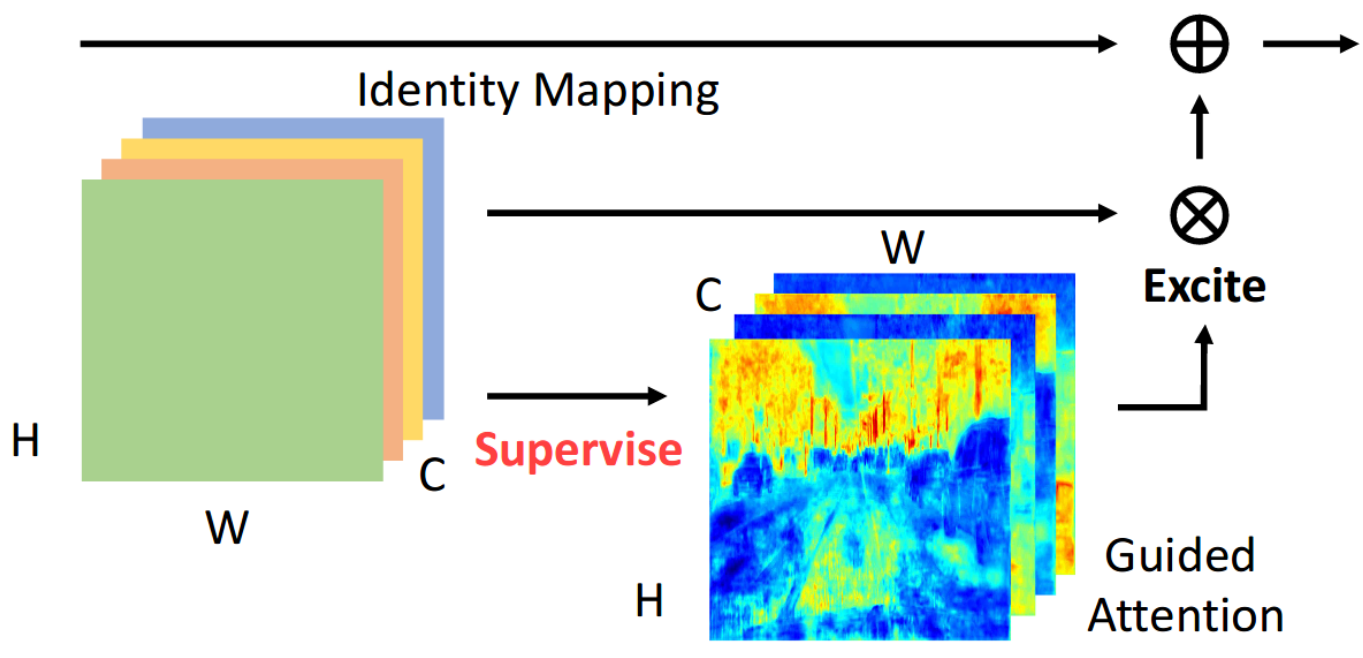 |
SPGNet: Semantic Prediction Guidance for Scene Parsing |
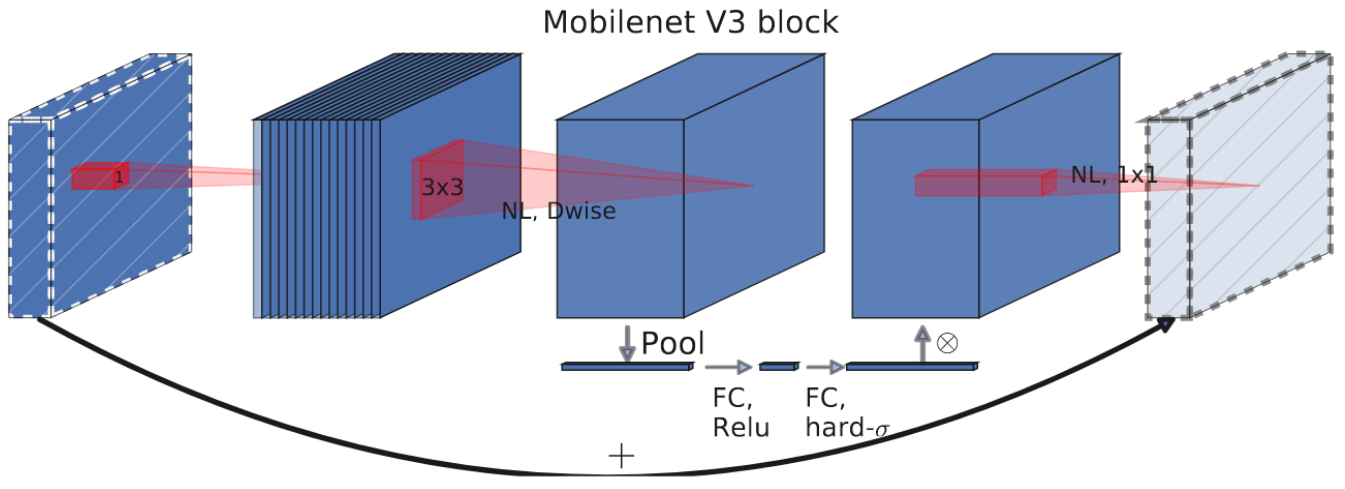 |
Searching for MobileNetV3 (oral) |
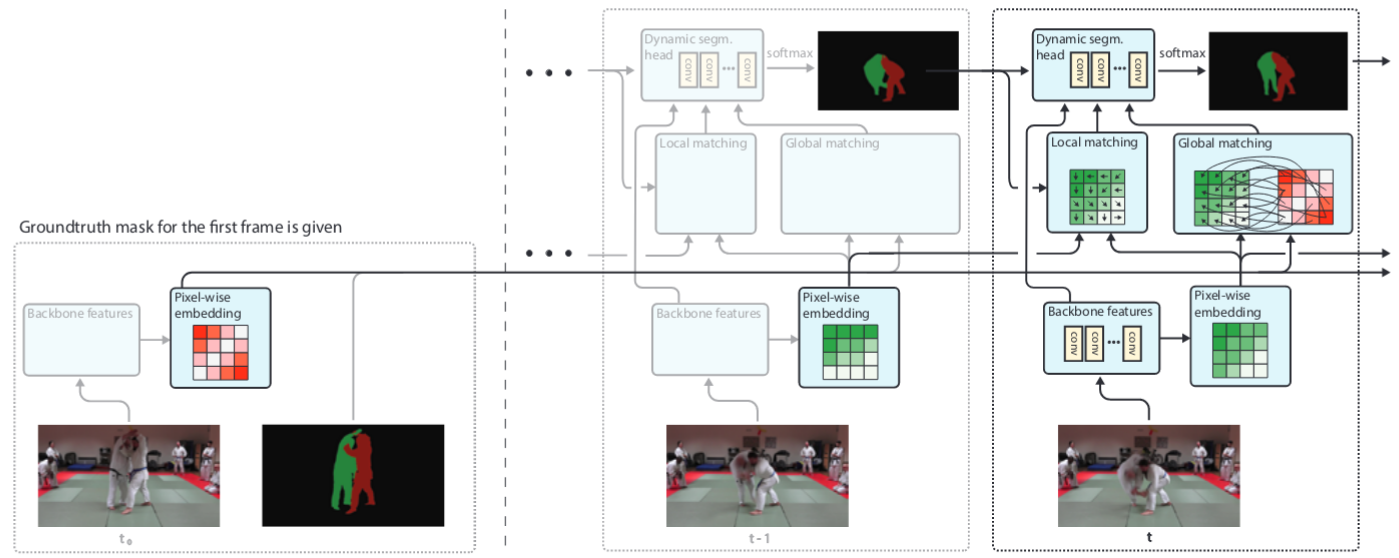 |
FEELVOS: Fast End-to-End Embedding Learning for Video Object
Segmentation |
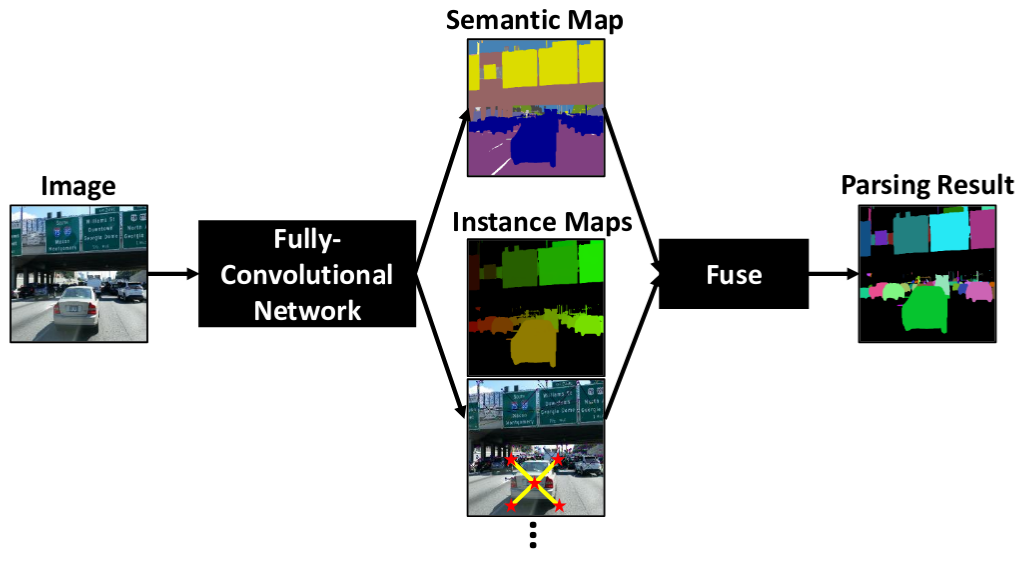 |
DeeperLab: Single-Shot Image Parser |
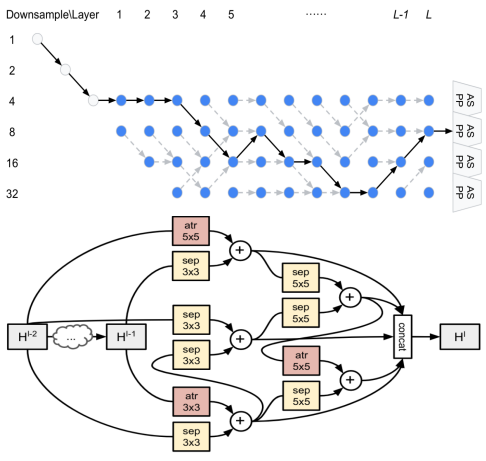 |
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation (oral) |
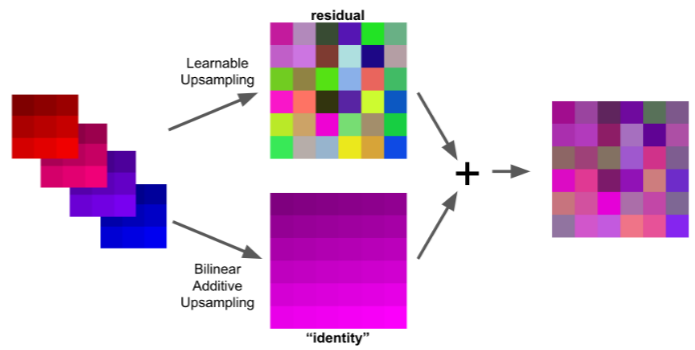 |
The Devil is in the Decoder: Classification, Regression and GANs |
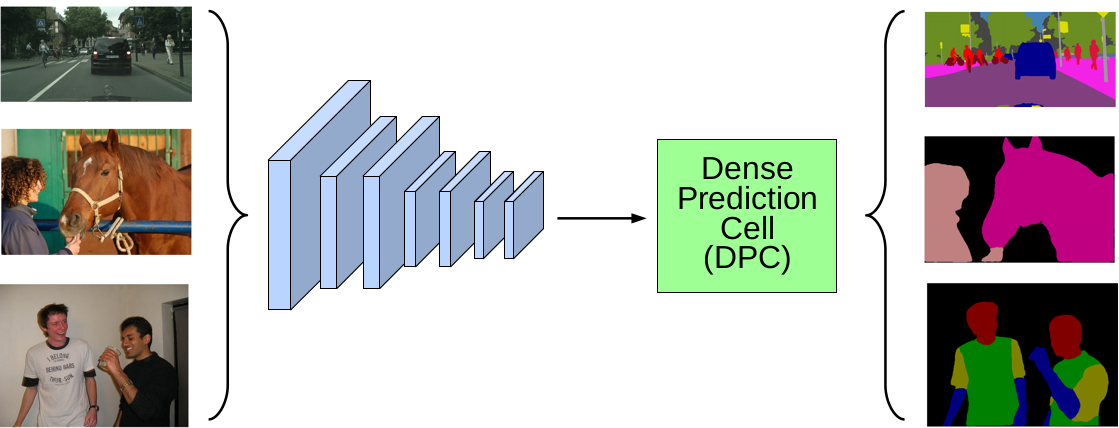 |
Searching for Efficient Multi-Scale Architectures for Dense Image
Prediction |
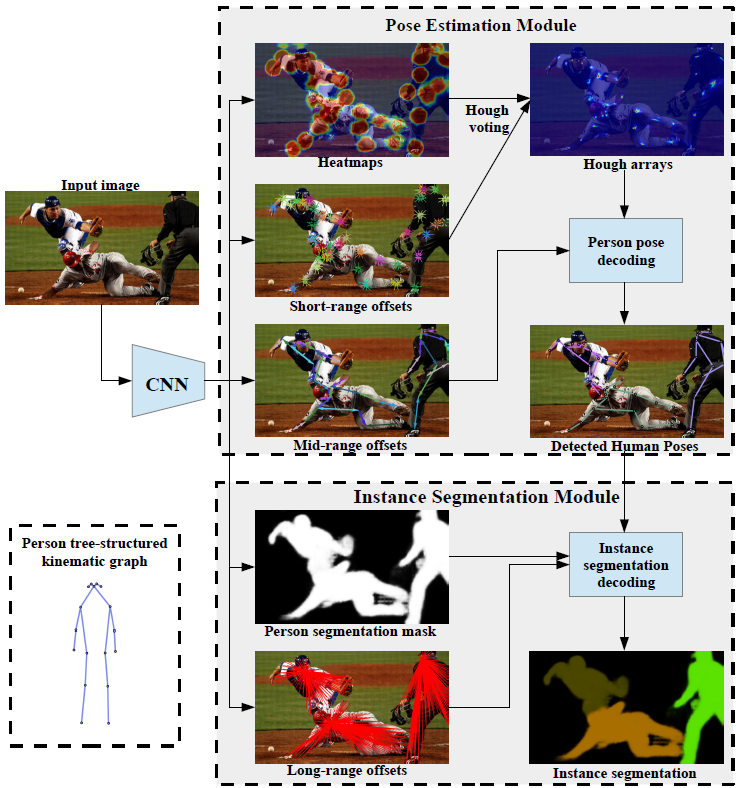 |
PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model |
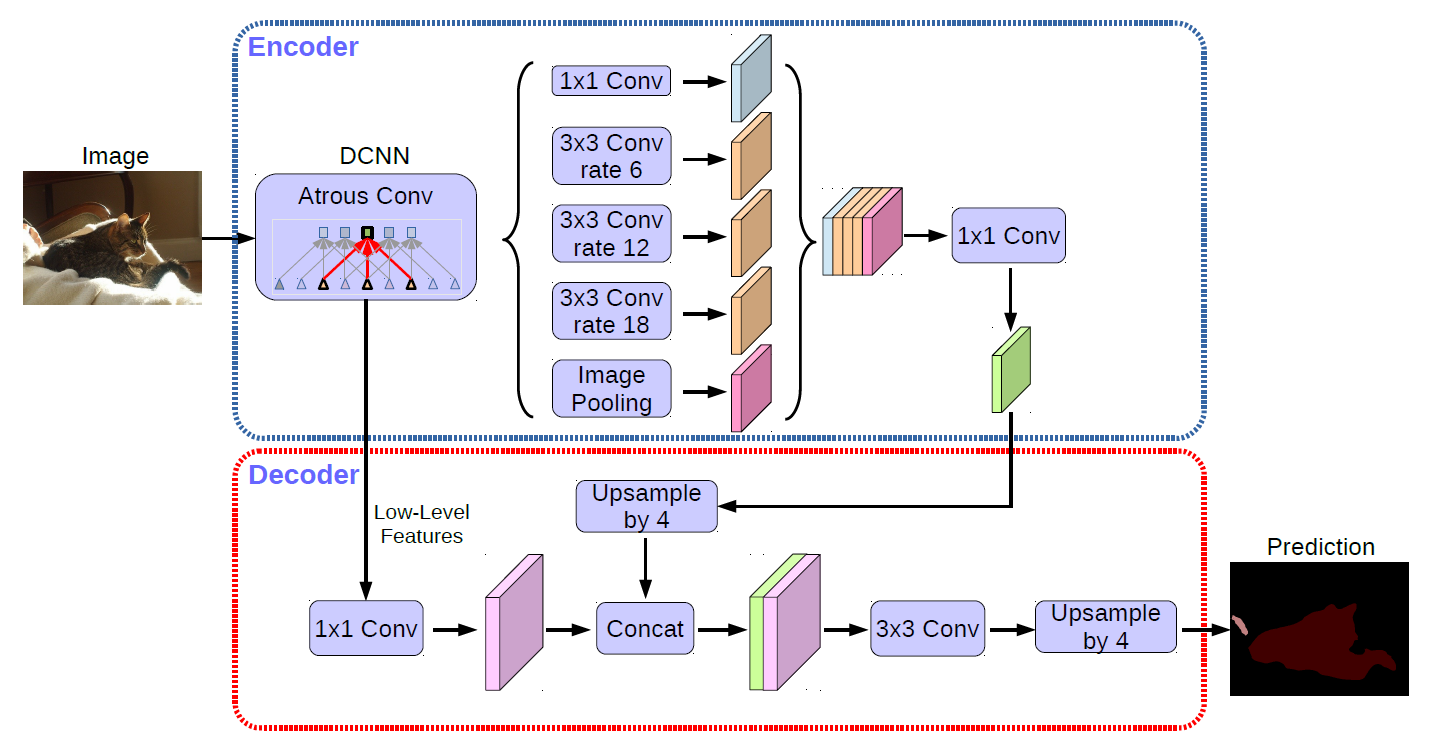 |
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation |
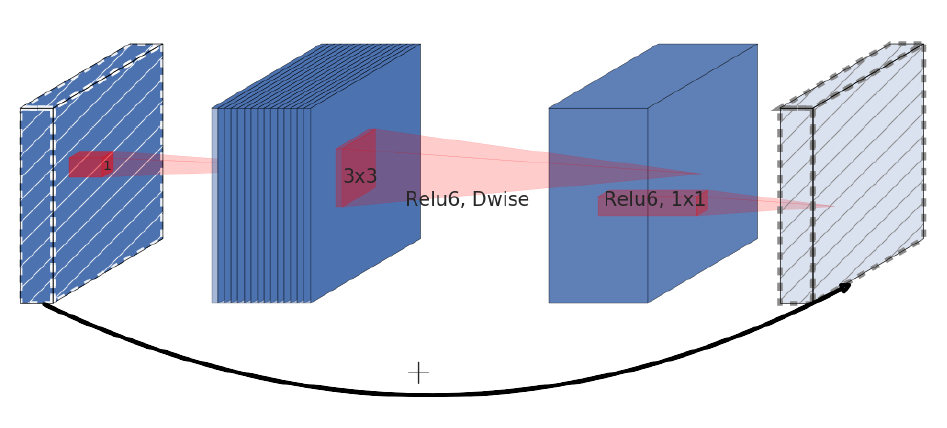 |
MobileNetV2: Inverted Residuals and Linear Bottlenecks |
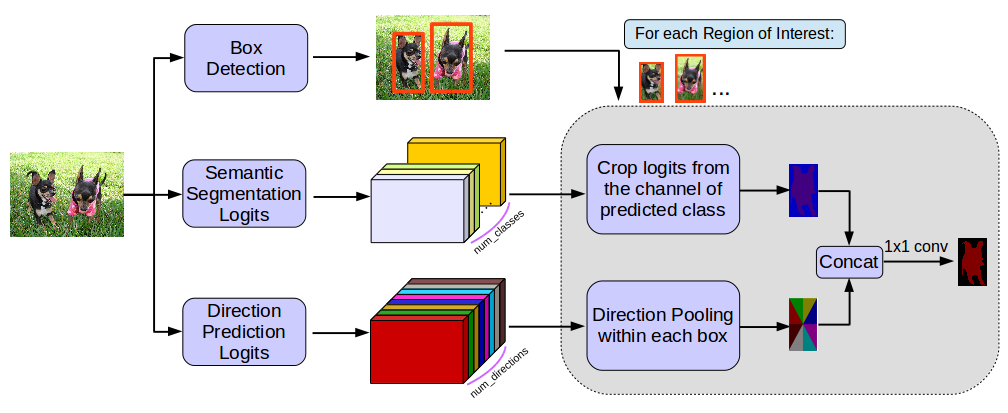 |
MaskLab: Instance Segmentation by Refining Object Detection with Semantic
and Direction Features |
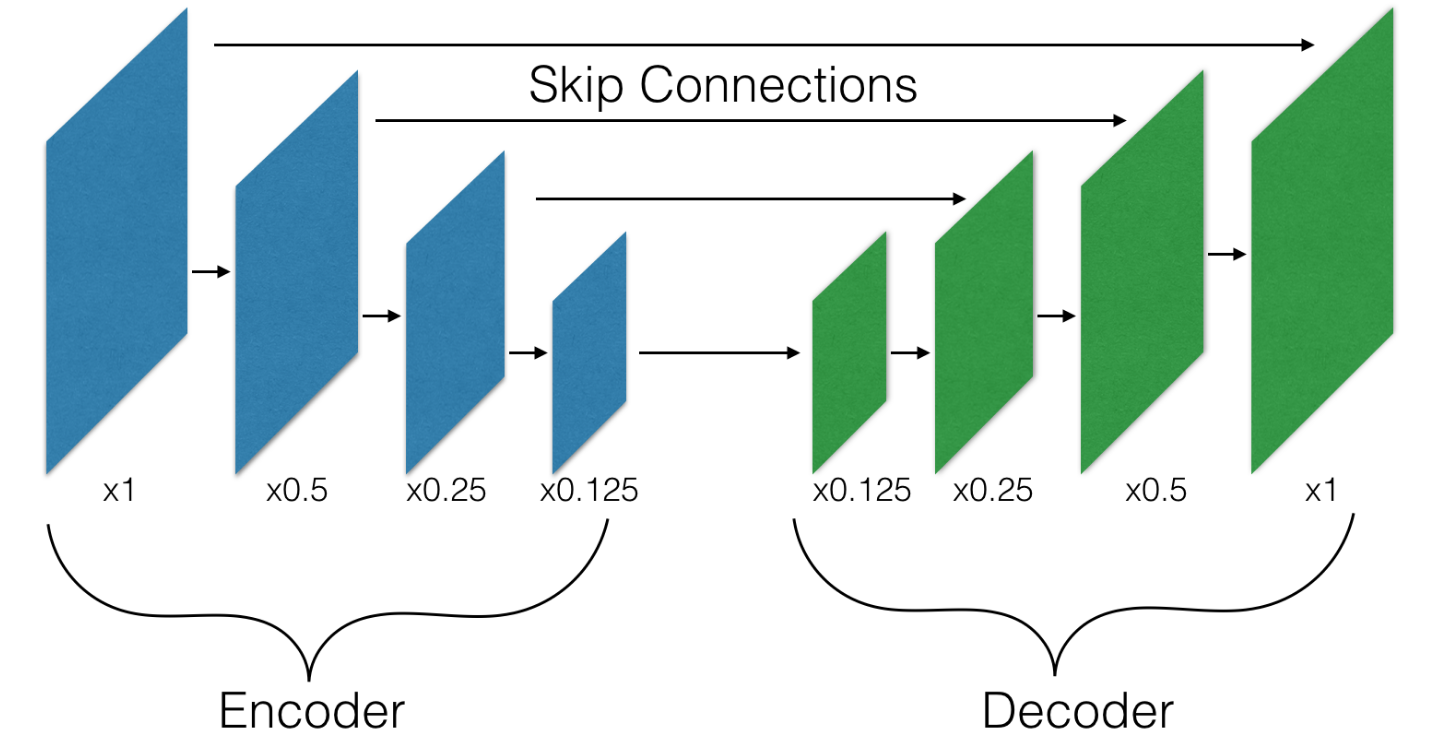 |
The Devil is in the Decoder |
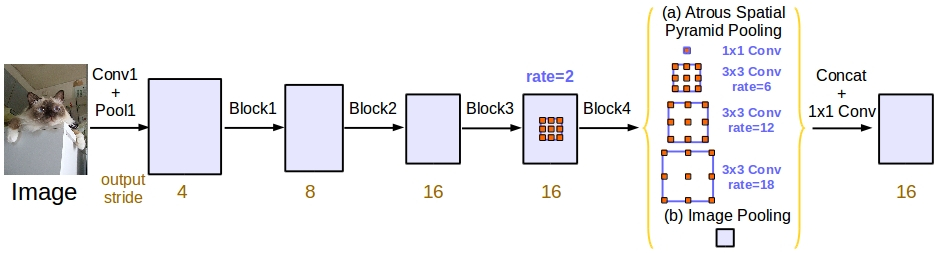 |
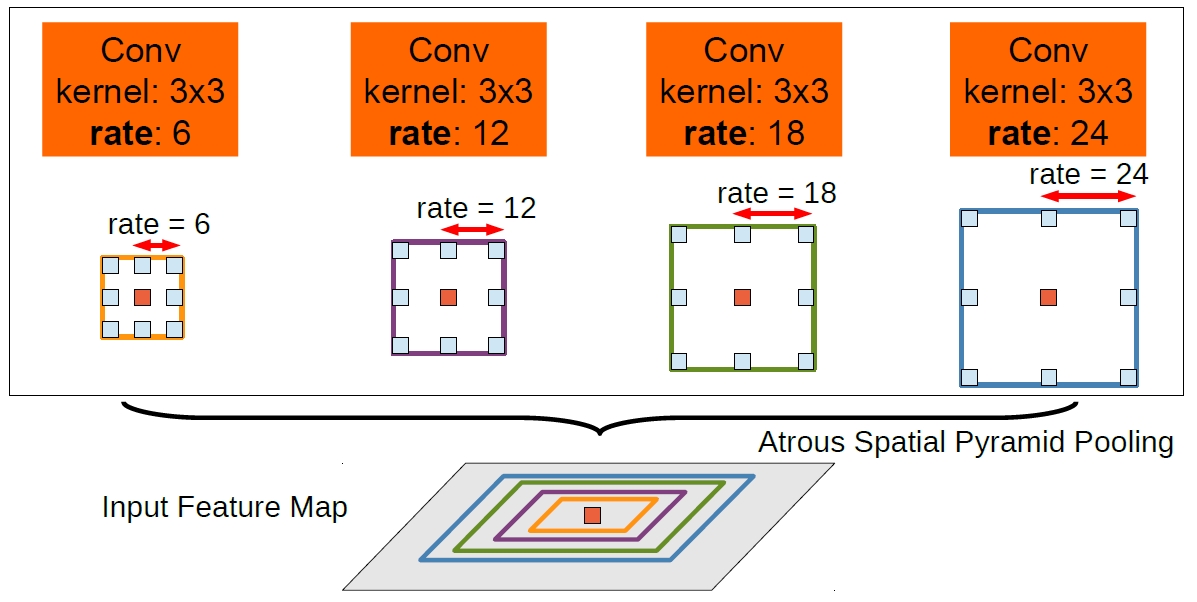
Rethinking Atrous Convolution for Semantic Image Segmentation |
 |
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs |
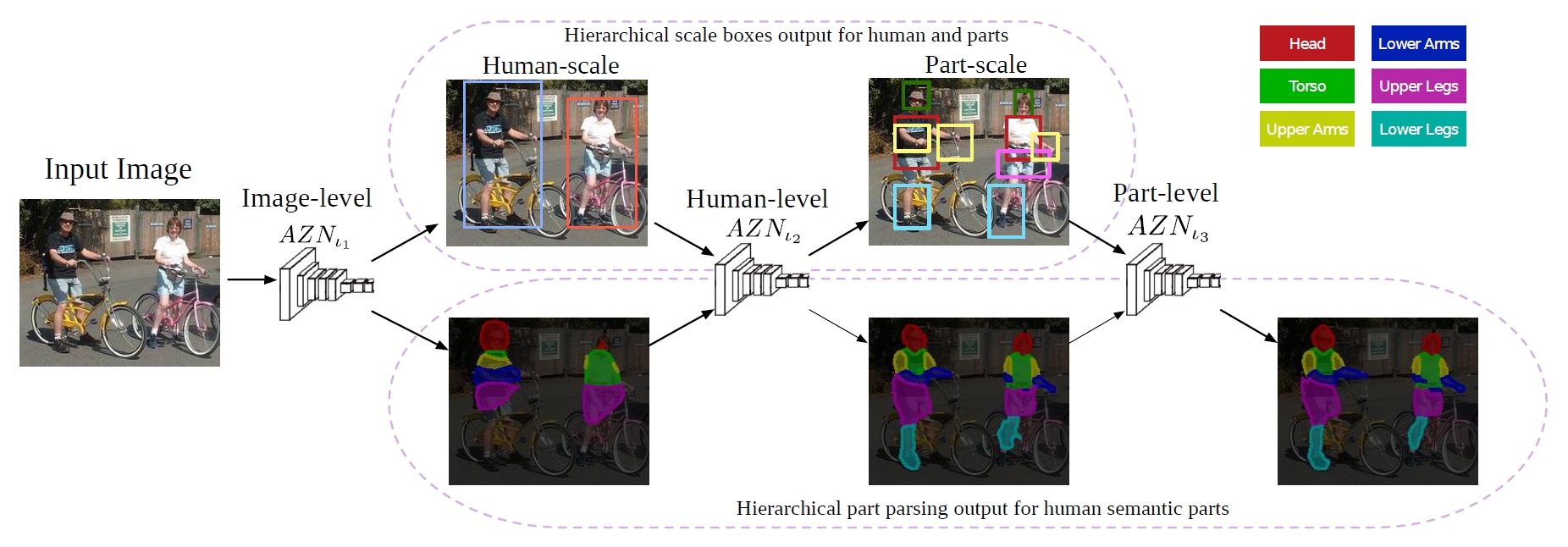 |
Zoom Better to See Clearer: Human Part Segmentation with Auto Zoom Net |
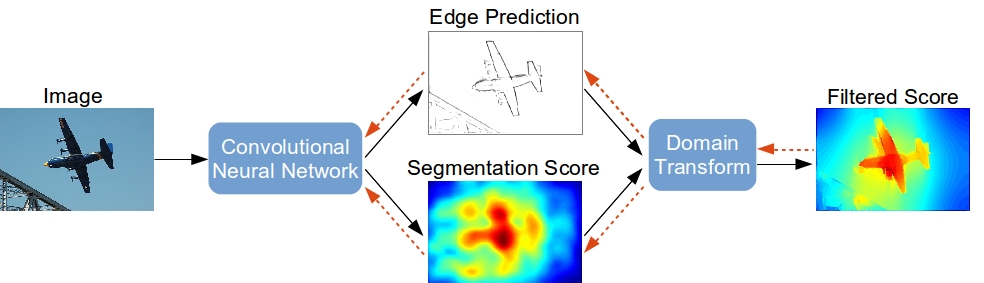 |
Semantic Image Segmentation with Task-Specific Edge Detection Using CNNs and a Discriminatively Trained Domain Transform |
 |
Attention to Scale: Scale-aware Semantic Image Segmentation |
 |
ABC-CNN: An Attention Based Convolutional Neural Network for Visual Question Answering |
 |
Weakly- and Semi-Supervised Learning of a Deep Convolutional Network for
Semantic Image Segmentation |
 |
Learning Deep Structured Models (oral) |
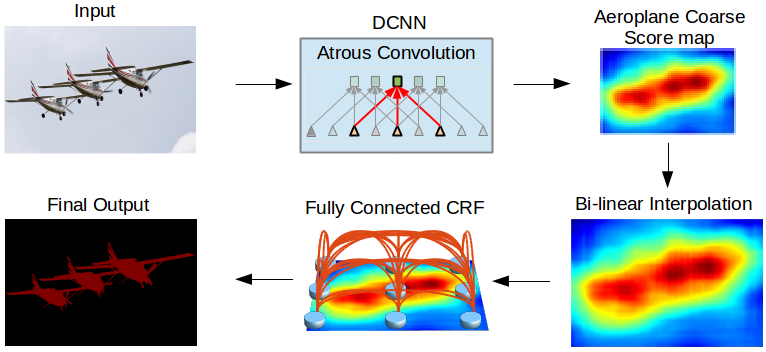 |
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs |
 |
Beat the MTurkers: Automatic Image Labeling from Weak 3D Supervision |
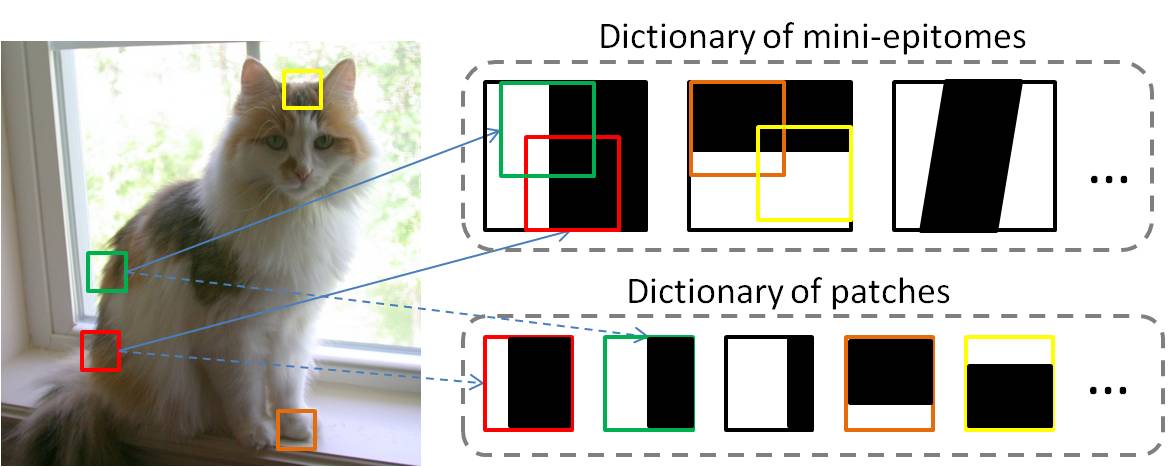 |
Modeling Image Patches with a Generic Dictionary of Mini-Epitomes |
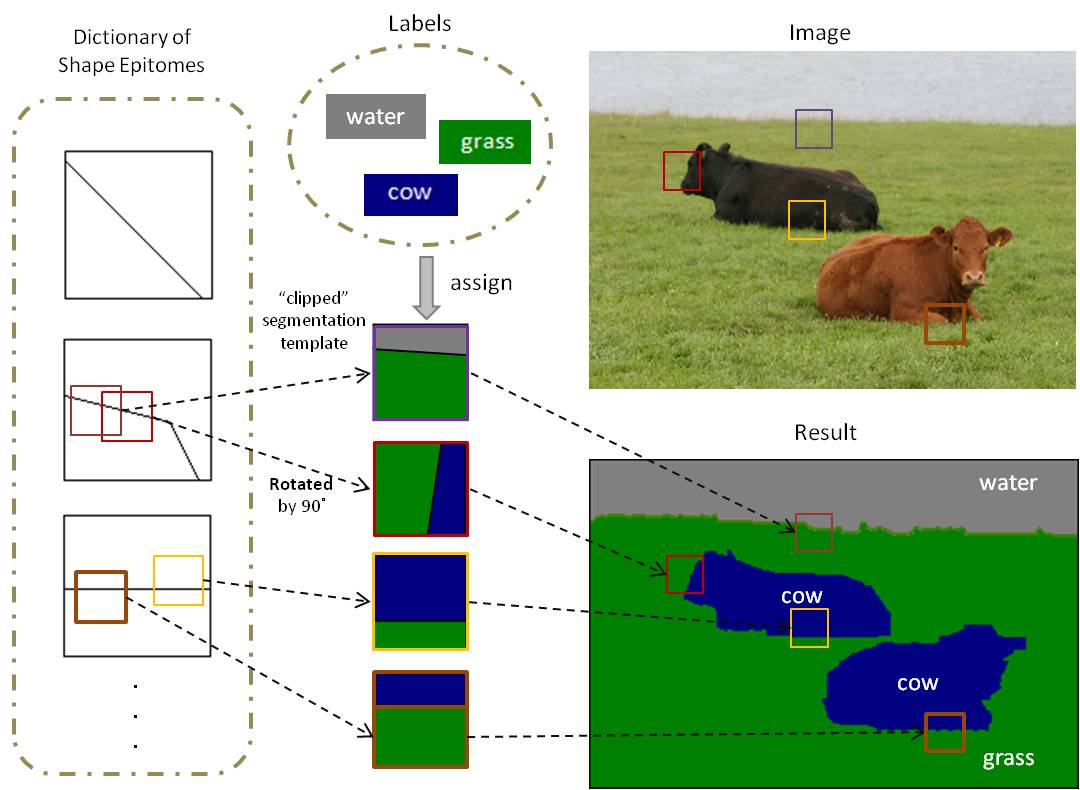 |
Learning a Dictionary of Shape Epitomes with Applications to Image Labeling |
Activities
Area Chair for ICCV 2019, CVPR 2020, 2023, 2024, ECCV 2020, 2024, NeurIPS 2022, 2024.
Reviewer for CVPR, ECCV, ICCV, NeurIPS.
Interns whom I had the pleasure to work with
While at ByteDance / TikTok:
Qihao Liu in Spring 2024. Ph.D. student at JHU.
Hosted with Qihang Yu.
Mark Weber in Fall 2023. Ph.D. student at TUM.
Hosted with Xueqing Deng, and Qihang Yu.
Inkyu Shin in Fall 2023. Ph.D. student at KAIST.
Hosted with Qihang Yu.
Jieneng Chen in Summer 2023. Ph.D. student at JHU.
Hosted with Qihang Yu.
Zhanpeng Zeng in Summer 2023. Ph.D. student at University of Wisconsin-Madison.
Hosted with Qihang Yu.
Ju He in Spring 2023. Ph.D. student at JHU.
Hosted with Qihang Yu, and Xueqing Deng.
While at Google:
Shuyang Sun in Fall 2022. Ph.D. student at University of Oxford.
Hosted with Weijun Wang.
Inkyu Shin in Summer 2022. Ph.D. student at KAIST.
Hosted with Jun Xie, and Dahun Kim.
Chenglin Yang in Summer 2022. Ph.D. student at JHU.
Hosted with Siyuan Qiao, and Yukun Zhu.
Jieru Mei in Spring 2022. Ph.D. student at JHU.
Hosted with Alex Zihao Zhu, Xinchen Yan, and Hang Yan.
Dahun Kim in Summer 2021. Finished Ph.D. at KAIST. Now at Google.
Hosted with Jun Xie.
Qihang Yu in Summer 2021. Ph.D. student at JHU.
Hosted with Maxwell Collins, and Yukun Zhu.
Mark Weber in Summer 2020. Ph.D. student at TUM.
Hosted with Jun Xie.
Siyuan Qiao in Summer 2020. Finished Ph.D. at JHU. Now at Google.
Hosted with Yukun Zhu.
Huiyu Wang in Summer 2019 and 2020. Finished Ph.D. at JHU. Now at Facebook.
Hosted with Yukun Zhu.
Jennifer Sun in Summer 2019. Currently: Ph.D. student at Caltech.
Hosted with Ting Liu.
Colin Graber in Summer 2019. Currently: Ph.D. student at UIUC.
Hosted with Michalis Raptis.
Bowen Cheng in Summer 2019. Finished Ph.D. student at UIUC. Now at Tesla.
Hosted with Yukun Zhu.
Chenxi Liu in Summer 2018. Finished Ph.D. at JHU. Now at Waymo.
Hosted with Wei Hua, and Li Fei-Fei.
Mason Liu in Summer 2018. Currently: Ph.D. student at Cornell.
Hosted with Ting Liu.
Paul Voiglaender in Summer 2018. Finished Ph.D. at RWTH Aachen University. Now at Google.
Hosted with Yuning Chai.
Tien-Ju Yang in Summer 2018. Finished Ph.D. at MIT. Now at Google.
Hosted with Xiao Zhang.
Jyh-Jing Hwang in Summer 2018. Finished Ph.D. at UPenn. Now at Waymo.
Hosted with Maxwell Collins.
Alexander Hermans in Summer 2017. Finished Ph.D. at RWTH Aachen University.
Hosted with Chao-Yeh Chen.
US Patents
Generating Panoptic Segmentation Labels, 2023
Jieru Mei, Hang Yan, Liang-Chieh Chen, Siyuan Qiao, Yukun Zhu, Alex Zihao Zhu, Xinchen Yan, Henrik Kretzschmar
Neural Architecture Search for Dense Image Prediction Tasks, 2018
Liang-Chieh Chen, Maxwell D. Collins, Yukun Zhu, George Papandreou, Barret Zoph, Florian Schroff, Hartwig Adam, and Jonathon Shlens.
Instance Segmentation, 2018
Liang-Chieh Chen, Alexander Hermans, George Papandreou, Florian Schroff, Peng Wang, and Hartwig Adam.
Highly Efficient Convolutional Neural Networks, 2018
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen.
Systems and Methods for Data Page Management of NAND Flash Memory Arrangements, November 2008
Liang-Chieh Chen and Xueshi Yang
Multi-Mode Encoding for Data Compression, February 2009
Liang-Chieh Chen and Xueshi Yang